- 여러 모델의 결과를 종합(synthesize) 하면 개별 모델 단독 성능을 크게 능가할 수 있다는 발견에서 출발
- 단일 프롬프트를 여러 전문가 모델이 병렬로 분석한 뒤 심판 모델(judge model) 이 결과를 종합해 최종 답변을 작성하는 멀티 모델 심의(multi-model deliberation) 방식
- 패널 모델은 웹 검색과 웹 페치를 활성화한 상태로 병렬 분석을 수행하며, 심판 모델이 합의, 모순, 부분적 일치, 고유 통찰, 사각지대를 구조화한 분석으로 정리
- 기본값은 Quality 프리셋이며, Budget 프리셋으로 저렴한 모델 전환 또는 fusion 플러그인 필드로 패널·심판 완전 재정의 가능
- 단일 모델로 충분치 않은 리서치, 전문가 비평, 오답 비용이 추가 완성 비용을 상회하는 상황에 적합
- 패널 구성원 전원과 심판 호출을 모두 실행하므로, 요청 비용은 단일 모델이 아닌 개별 완성(completion) 합산 방식으로 책정
동작 방식
- 단일 프롬프트를 소규모 멀티 모델 심의로 전환하는 방식
- 전문가 모델 패널이 웹 검색(web search) 과 웹 페치(web fetch) 를 활성화한 상태로 프롬프트를 병렬 분석
- 심판 모델이 패널 응답을 종합해 합의(consensus), 모순(contradictions), 부분 커버리지(partial coverage), 고유 통찰(unique insights), 사각지대(blind spots) 로 구조화한 분석 생성
- 구조화된 분석을 기반으로 심판 모델이 최종 답변 작성
패널 구성 및 설정
- 기본 패널은 Quality 프리셋 사용
- 더 저렴한 구성원을 원하면 Budget 프리셋 으로 전환 가능
- fusion 플러그인의
analysis_models및model필드로 패널과 심판을 완전히 재정의(override) 가능
- 단일 모델이 충분치 않을 때 사용 권장
- 리서치, 전문가 비평, 또는 오답 비용이 추가 완성 비용을 초과하는 영역에 적합
가격 및 제약
- 패널 구성원 전원과 심판 호출을 모두 실행하므로, 요청 비용은 단일 모델 기준이 아닌 개별 완성의 합산으로 책정
- 실제 실행된 모델 확인은 Activity 페이지에서 가능
- 컨텍스트 한도는 선택한 모델에 따라 달라짐
프리셋에서는 6개의 모델을 사용
- 최고 품질: Claude Opus, OpenAI GPT, Google Gemini Pro
- 최저 비용: Google Gemini Flash, DeepSeek V4 Flash, MoonshotAI Kimi
관련 발표: "Fusion으로 프론티어 성능을 넘어서다"
- 여러 모델의 결과를 종합해 개별 모델 단독 성능을 능가하는 도구로, 참가 모델 패널과 결과를 융합하는 judge 모델을 직접 선택해 단일 모델처럼 호출
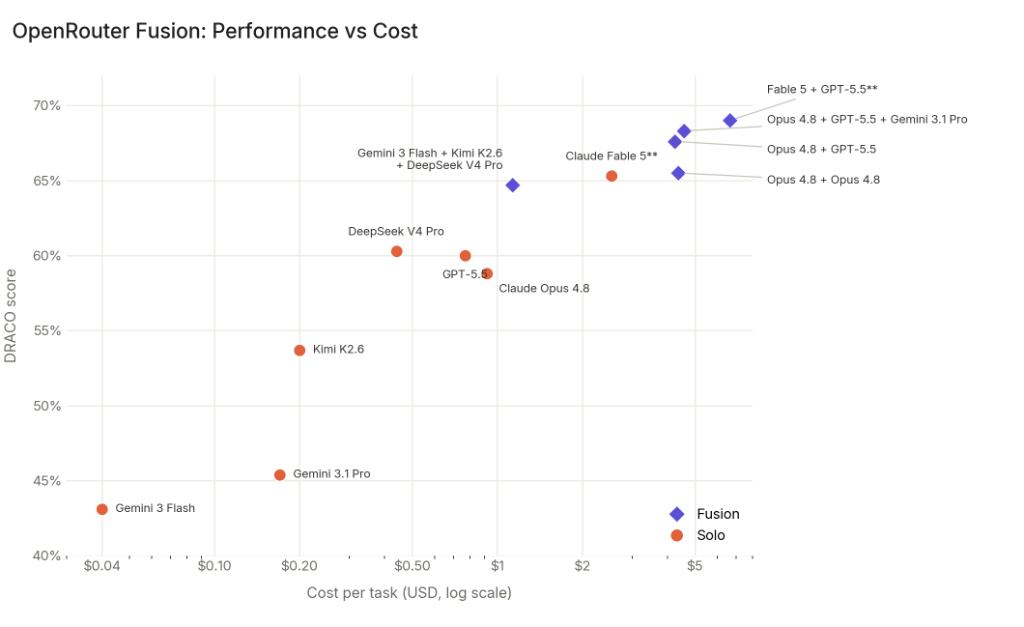
- DRACO 벤치마크의 deep research 과제 100개 측정에서 패널이 개별 모델을 일관되게 능가
- Fable 5 + GPT-5.5 융합이 69.0% 로 단독 Fable 5(65.3%) 포함 모든 개별 모델 능가
- 저가형 패널(Gemini 3 Flash + Kimi K2.6 + DeepSeek V4 Pro)이 비용 50% 로 Fable 5 점수에 1% 이내 근접, GPT-5.5·Opus 4.8 능가
- 프롬프트를 패널 모델에 병렬 전송, judge가 합의점·모순·고유 통찰·맹점을 분석하고 호출 모델이 이를 근거로 최종 답변 작성
- 전체 파이프라인이 server-side에서 실행되어 개별 모델 호출과 동일한 방식으로 사용 가능
- Opus 4.8을 자기 자신과 융합한 경우에도 65.5%로 단독(58.8%) 대비 6.7점 상승, synthesis 단계 자체의 효과 확인
- 패널 모델이 채점 루브릭을 온라인에서 찾는 오염 위험 발견, web search·web fetch 제외 목록을 한 줄 설정으로 적용해 차단
- 사용 방법 4가지: Chatroom(코드 불필요), Model slug(문자열 교체), Server tool(최고 수준 제어), Plugin(패널 지정)
- Fable의 drop-in 대체재 아님, Fable이 강점인 long-horizon 과제는 미포함, 코딩에서는 선택적 호출 도구로 활용
{kind=link}