LLM4Decompile - LLM을 활용한 바이너리 코드 디컴파일 기술
(github.com/albertan017)- LLM4Decompile은 Linux x86_64 바이너리를 GCC O0~O3 최적화 수준에서 사람이 읽을 수 있는 C 소스 코드로 되돌리는 오픈소스 대형 언어 모델 프로젝트임
- 접근 방식은 바이너리를 Objdump로 어셈블리로 변환한 뒤 LLM이 C 코드로 디컴파일하는 흐름이며, Ghidra 출력 의사코드를 정제하는 LLM4Decompile-Ref 계열도 제공함
- 모델은 1.3B~22B 규모로 공개되어 있고, llm4decompile-9b-v2는 Decompile 벤치마크에서 재실행 가능률 64.9%를 기록함
- 평가 지표는 디컴파일된 코드가 미리 정의된 테스트를 통과해 제대로 실행되는지 보는 재실행 가능률이며, HumanEval-Decompile 164개 C 함수와 ExeBench 2,621개 함수가 벤치마크로 사용됨
- 프로젝트는 2025년에 decompile-bench와 SK²Decompile을 공개했으며, 더 많은 아키텍처·설정·디컴파일 도구 연계를 목표로 확장 중임
LLM4Decompile의 목표와 지원 범위
- LLM4Decompile은 디컴파일에 특화된 오픈소스 대형 언어 모델 프로젝트임
- 현재 버전은 Linux x86_64 바이너리를 GCC 최적화 수준 O0~O3 범위에서 사람이 읽을 수 있는 C 소스 코드로 디컴파일함
- 프로젝트는 더 넓은 아키텍처와 설정을 지원하기 위한 확장을 진행 중임
- 두 가지 주요 사용 방식이 있음
- LLM4Decompile-End: 바이너리를 직접 디컴파일하는 모델 계열
- LLM4Decompile-Ref: Ghidra가 디컴파일한 의사코드를 LLM으로 정제하는 모델 계열
디컴파일 학습·평가 흐름
- 컴파일 과정은 C 소스 코드에서 시작해 전처리, 컴파일, 어셈블, 링크를 거쳐 실행 파일을 생성함
- 디컴파일은 이 과정을 반대로 따라가며, 바이너리 코드를 다시 소스 파일로 변환함
- LLM은 바이너리 데이터를 직접 처리하지 못하므로, 바이너리를 먼저 Objdump로 어셈블리 언어로 디스어셈블해야 함
- README는 바이너리와 디스어셈블된 ASM이 서로 변환 가능하므로 동등하게 취급된다고 설명함
- 학습에서는 디컴파일된 코드와 원본 소스 코드 사이의 손실을 계산하고, 평가는 테스트 어서션을 통과하는지로 기능성을 확인함
평가 지표와 벤치마크
- 핵심 지표는 Re-executability임
- 디컴파일된 코드가 제대로 실행되는지 확인함
- 미리 정의된 모든 테스트 케이스를 통과하는지 평가함
- HumanEval-Decompile은 표준 C 라이브러리에만 의존하는 164개 C 함수 모음임
- ExeBench는 실제 프로젝트에서 가져온 2,621개 함수 모음임
- 사용자 정의 함수, 구조체, 매크로를 포함함
공개 모델과 성능
- LLM4Decompile은 1.3B~33B 파라미터 규모의 모델을 포함하며, 모델은 Hugging Face에 공개됨
- 주요 모델의 재실행 가능률은 다음과 같음
- llm4decompile-1.3b-v1.5: 1.3B, 27.3%
- llm4decompile-6.7b-v1.5: 6.7B, 45.4%
- llm4decompile-1.3b-v2: 1.3B, 46.0%
- llm4decompile-6.7b-v2: 6.7B, 52.7%
- llm4decompile-9b-v2: 9B, 64.9%
- llm4decompile-22b-v2: 22B, 63.6%
- V1.5 계열은 15B 토큰의 더 큰 데이터셋과 최대 토큰 길이 4,096으로 학습되었고, 이전 모델 대비 100% 이상 성능 향상이 있었다고 밝힘
- V2 계열은 Ghidra 기반이며, Ghidra가 만든 디컴파일 의사코드를 정제하도록 2B 토큰으로 학습됨
- 22B-V2는 6.7B-V1.5보다 추가로 40.1% 높은 성능을 보였다고 밝힘
최근 공개 항목
- 2025년 10월 4일 SK²Decompile이 공개됨
- 1단계 Structure Recovery, 즉 Skeleton 단계는 바이너리나 의사코드를 난독화된 중간 표현으로 변환함
- 2단계 Identifier Naming, 즉 Skin 단계는 의미 있는 식별자를 가진 사람이 읽을 수 있는 소스 코드를 생성함
- 모델 링크: sk2decompile-struct-6.7b, sk2decompile-ident-6.7
- 2025년 5월 20일 decompile-bench가 공개됨
- 학습용 바이너리-소스 함수 쌍 200만 개 포함
- 평가용 함수 쌍 7만 개 포함
- 세부 내용은 decompile-bench 폴더에 있음
- 2024년 10월 17일 decompile-ghidra-100k가 공개됨
- 최적화 수준별 25,000개씩 총 100,000개 학습 샘플 포함
- 단일 A100 40G GPU에서 약 3.5시간에 실행되는 학습 스크립트를 제공함
- 빠른 재현 비용은 총 20달러 미만이며, 재실행 가능률 0.26을 달성함
- 2024년 9월 23일 LLM4Decompile-9B-v2가 공개됨
- Yi-Coder-9B를 기반으로 파인튜닝됨
- Decompile 벤치마크에서 재실행 가능률 0.6494를 달성함
사용 흐름
- 빠른 시작은 저장소 복제, Conda 환경 생성,
requirements.txt설치로 구성됨 - 전처리 단계는 C 코드를 GCC로 바이너리로 컴파일한 뒤,
objdump -d로 어셈블리 명령어를 추출함 - 함수 이름은 예제의
func0대신 디컴파일하려는 함수명으로 바꿔야 함 - 입력 어셈블리는 다음 형태를 기대함
<FUNCTION_NAME>:- 이어지는 여러 줄의 어셈블리 명령어
- 디컴파일 단계는
transformers의AutoTokenizer와AutoModelForCausalLM으로 Hugging Face 모델을 불러와 어셈블리 프롬프트를 C 코드로 생성함 - Docker 사용도 가능함
- 이미지를 빌드한 뒤 GPU 옵션으로 컨테이너를 실행함
ghidra디렉터리에서demo.py를 실행하는 흐름을 제공함
HumanEval-Decompile 데이터 형식
- HumanEval-Decompile 데이터는
llm4decompile/decompile-eval/decompile-eval-executable-gcc-obj.json에 JSON 리스트 형식으로 저장됨 - 샘플 수는 164개 함수에 O0, O1, O2, O3 최적화 수준을 곱한 164*4개임
- 각 샘플은 5개 키를 가짐
task_id: 문제 IDtype: O0, O1, O2, O3 중 하나인 최적화 단계c_func: HumanEval 문제의 C 해답c_test: C 테스트 어서션input_asm_prompt: 어셈블리 명령어와 프롬프트
- 평가 스크립트는 evaluation 폴더에 있음
진행 중인 항목과 라이선스
- 진행 항목에는 더 큰 학습 데이터셋과 정리 과정, 인기 언어·플랫폼·설정 지원, 실행 파일 지원, Ghidra·Rizin 같은 디컴파일 도구 통합이 포함됨
- 더 큰 학습 데이터셋과 실행 파일 지원은 2024년 5월 13일 완료된 항목으로 표시됨
- 코드 저장소는 MIT License와 DeepSeek License로 라이선스가 부여됨
- 논문은 arXiv:2403.05286에 있으며, 프로젝트는 Colab과 YouTube 자료도 제공함
댓글과 토론
Hacker News 의견들
-
흥미로운 아이디어지만, 결과가 신뢰 가능할지가 궁금함
다시 컴파일하면 다른 기계어가 나올 수 있어서 환각을 식별하기 어렵고, 특히 코드의 핵심일 수 있는 새로운 구조에서 조용히 실패할까 걱정됨
생성 방식으로 실행할 때 LLM이 특정 구간의 확신도를 함께 보고하는 방법이 있는지 궁금하고, 결국 사람의 확인이 필요할 듯함- 그래서 왕복 변환이 중요함
바이너리를 소스로 역컴파일한 뒤 다시 바이너리로 컴파일했을 때 원래 바이너리가 나와야 하고, 손실이 허용 가능한 수준까지 떨어질 때까지 반복하면 됨
이런 문제에는 강화학습이 매우 잘 맞고, 실제로 이런 유형에서 비정상적으로 효과적인 것으로 알려져 있음 - LLM은 본질적으로 확률적이라 자연어 처리처럼 정밀하지 않은 영역에서는 꽤 잘 동작하지만, 역컴파일이나 역어셈블리에 쓰는 건 개인적으로 “도구 선택이 틀린” 경우에 가깝다고 봄
요즘 흔한 “그냥 LLM 쓰자” 밈을 탐색해보는 실험일 수는 있겠지만, 기존 역컴파일러가 훨씬 적은 연산으로 이미 더 잘한다는 점이 더 큰 반론임 - 입력, 출력, 그리고 입력이 출력의 의미와 일치한다는 형식 증명을 받는 형식 검증 도구를 두고, LLM이 출력과 함께 그 증명도 만들게 하면 됨
이후 검증 도구로 LLM이 제공한 증명에 따라 결과가 맞는지 확인할 수 있음
물론 그런 증명을 만들 수 있는 LLM을 구축하고 학습시키는 것이 더 큰 난제겠지만, 환각을 안전하게 잡는 방법이 될 수 있음 - 차등 퍼징을 써도 됨
- 완전히 신뢰 가능하지 않더라도, 바이너리를 수정할 때는 보통 몇몇 함수만 바꾸면 충분한 경우가 많음
따라서 그 몇 함수만 다시 컴파일하면 됨
- 그래서 왕복 변환이 중요함
-
애플리케이션을 만든 개발자를 알고 있다면, 그들의 과거 코드를 학습 데이터로 써서 역컴파일 모듈을 훈련할 수 있을지 흥미로움
예를 들어 Super Mario 64와 Zelda 64는 완전히 역컴파일됐고 다른 N64 게임들도 진행 중이니, 두 게임에 참여한 개발자를 매핑하고 누가 어떤 모듈을 만들었는지까지 추정해 다른 게임 역컴파일에 활용할 수 있을지 궁금함
이게 정말 좋아지면 PC 안의 모든 바이너리 블롭을 해독하고 드라이버를 공개하며, OS까지 열어젖히는 삶도 꿈꿀 수 있음
Linux에 만족하지 않고 Windows XP를 되살려 현대 보안과 앱 호환성을 백포트한 뒤 Microsoft의 Windows 11은 그대로 두는 상상도 가능함- 역컴파일러는 이미 존재하고 성능도 좋음
LLM이 기존 역컴파일러와 같은 일을 할 수 있다면 변호사들은 그걸 동등한 절차로 볼 가능성이 큼
핵심 문제는 기술이 아니라 법적·정치적 문제임 - 학사논문에서 비슷한 주제를 다뤘는데, 특정 조건에서는 컴파일된 바이너리만 보고도 누가 프로그램을 작성했는지 맞히는 작성자 식별 분류기를 학습할 수 있다는 연구가 있었음
실제로 유용하게 쓰인 사례는 잘 모르지만, 개인의 코딩 스타일이 컴파일 과정을 거친 뒤에도 남아서 서로의 컴파일된 프로그램을 구분할 수 있다는 점이 멋짐 - 실제 작성된 코드 자체를 식별할 수는 없을 것 같음
결과는 원본과 매우 비슷하겠지만 많은 코드 스타일 요소가 사라지고, 남아 보이는 스타일도 대체로 환각에 가까울 듯함
- 역컴파일러는 이미 존재하고 성능도 좋음
-
공개 C 코드로 대량의 입력/출력 쌍 데이터셋을 만들기 쉬워서, 이건 LLM 미세조정에 아주 좋은 활용 사례임
- 코딩 LLM, 예를 들어 DeepSeek 같은 모델로 매우 많은 C 코드를 생성하고 컴파일 여부를 검증해 합성 학습 데이터로 쓰는 것도 이 상황에서는 꽤 유리할 것 같음
보통 합성 학습 데이터의 품질이 큰 걱정거리지만, 여기서는 코드가 컴파일된다는 사실이 핵심임
- 코딩 LLM, 예를 들어 DeepSeek 같은 모델로 매우 많은 C 코드를 생성하고 컴파일 여부를 검증해 합성 학습 데이터로 쓰는 것도 이 상황에서는 꽤 유리할 것 같음
-
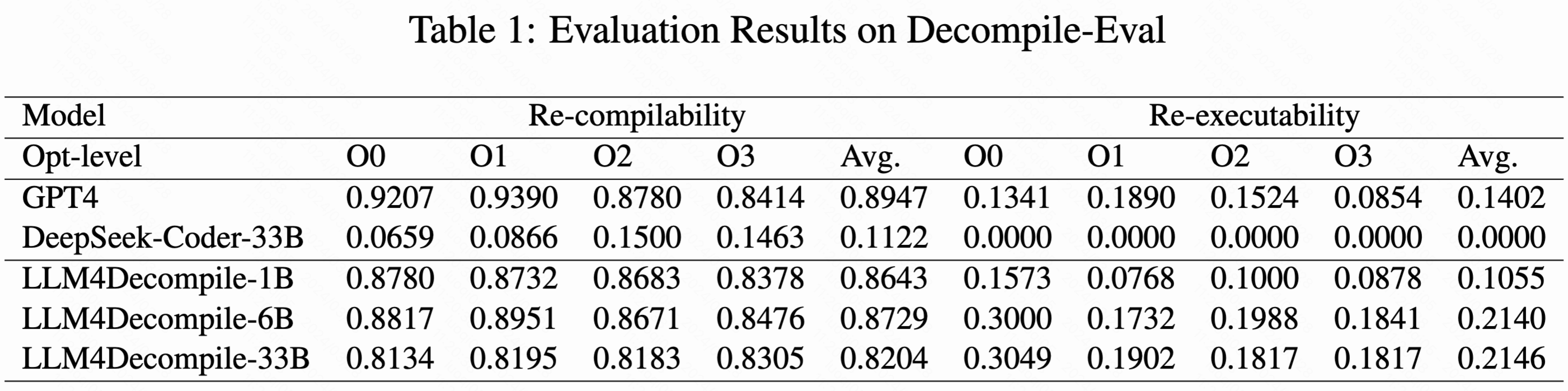
결과 그림의 재실행 가능성 수치를 제대로 읽은 것이라면, 아이디어는 훌륭하지만 실제로는 잘 작동하지 않는 듯함
https://raw.githubusercontent.com/albertan017/LLM4Decompile/...
보충하면, 재실행 가능성은 의미적 정확성을 재는 핵심 척도임
역컴파일 결과를 다시 컴파일하고 테스트 케이스를 실행해 프로그램 논리와 동작이 보존됐는지 평가하며, 재컴파일 가능성과 재실행 가능성은 각각 구문 복원과 의미 보존을 나타냄 -
이 문제는 적어도 두 가지 면에서 흥미로움
첫째, 이상적인 역컴파일러는 독점 소스 코드의 의미를 약화시킬 수 있음
둘째, 공개된 C 코드가 풍부해서 어셈블리와 소스 코드의 쌍 데이터셋을 쉽게 만들 수 있고, 최적화 수준·컴파일러·플랫폼도 다양함
다만 왜 저자들이 DeepSeek-Coder를 미세조정했는지 궁금함
비슷한 데이터셋으로 LLM을 처음부터 학습할 수 있는지, 어느 정도 크기가 필요한지, 로컬 실행이 가능한지도 궁금함- 대부분의 독점 코드는 방화벽 뒤에서 실행되므로 이런 방식의 영향을 크게 받지 않을 것임
원하는 작업이 초기 모델과 아주 가깝지 않더라도, 무작위 초기화보다 사전학습 모델에서 시작하는 편이 거의 항상 낫다 - 이상적인 역컴파일러는 존재하지 않음
컴파일러가 정보를 잃기 때문에 어떤 의미에서는 결코 존재할 수 없고, “결과 코드의 고수준 이해”라는 관대한 관점으로 봐도 이건 컴퓨터 보안 분야의 범용 인공지능급 문제임
아직 아무도 여기에 가까이 가지 못했음 - 언어 모델을 처음부터 학습하는 건 데이터가 많이 필요함
Llama2는 2조 토큰으로 개발됐지만, 이 데이터셋은 약 40억 토큰 수준임
적절한 모델 크기도 단순히 정하기 어렵고, 실험에서는 70억 매개변수 모델이 21% 실행 가능성을 보인 반면 10억 매개변수 모델은 10%에 그쳤음
다만 재컴파일 가능성은 둘이 꽤 비슷함
10억 매개변수 모델은 최소 2GB GPU 메모리가 필요해 대부분의 GPU에서 가능하고, 70억 모델은 14GB가 필요해 3090/4090 계열에 적합함
330억 모델은 단일 카드로는 A100 80GB가 선택지이고, 기술적으로 MacBook에서도 가능하겠지만 실제로 쓰고 싶지는 않을 것임 - 학습 비용과 미세조정 비용 차이 때문일 것 같음
아이디어를 검증하기 위한 출발점일 수도 있음
- 대부분의 독점 코드는 방화벽 뒤에서 실행되므로 이런 방식의 영향을 크게 받지 않을 것임
-
Python 바이트코드용 LLM 기반 역컴파일러 https://github.com/kukas/deepcompyle를 만들고 있음
이 연구 방향으로 작업하는 사람이 많지 않은 것 같지만, 특히 긴 주의 문맥이 가능해지는 지금은 꽤 흥미로울 수 있다고 봄
이 분야를 다루는 팀을 아는 사람이 있다면 협업에 관심 있음- Python 바이트코드에 LLM을 쓰는 이점이 있는지 궁금함
경험상 Python 바이트코드는 충분히 고수준이라 소스 코드로 직접 변환할 수 있음 - 왜 Python인지 궁금함
Python은 대규모 오픈소스 라이브러리 생태계가 있지만, 바이너리 형태로 배포되는 소프트웨어에 많이 쓰인다고 보지는 않음 - PyLingual이 있지만 아쉽게도 오픈소스는 아님
LLM 기반인지도 확실하지 않음 - 역컴파일 작업은 C 쪽이 많은 것 같음
바이너리로 컴파일되는 Python 프로젝트는 많지 않아 보임
- Python 바이트코드에 LLM을 쓰는 이점이 있는지 궁금함
-
이런 걸 해보려고 계획 중이었음
언젠가는 누군가 바이너리 입력 → 좋은 소스 코드 출력 파이프라인을 뚫겠지만, 아직 몇 년은 걸릴 것 같음
이 문제 끝에 큰돈이 쌓여 있지는 않아 보여서 그렇게 보지만, 틀릴 수도 있음
좋은 임시 접근은 Ghidra를 헤드리스 모드로 돌리는 역컴파일 파이프라인을 만들고, 역컴파일러의 엄격한 구문 정확성과 LLM의 직관적 능력을 결합하는 것임
AlphaGeometry처럼 역컴파일러와 LLM이 서로의 약점을 보완해야 함: https://deepmind.google/discover/blog/alphageometry-an-olymp...
또한 AICI 같은 것을 접착제로 써서 C 소스 생성을 조율하는 방식이 필요함: https://github.com/microsoft/aici
LLM의 가중치를 문법적으로 올바른 C 소스 생성에 쓰기보다는, 변수명·스니펫 패턴·아키텍처 선택을 생각하게 하고 Ghidra나 LLVM 같은 도구가 나머지를 맡는 편이 바람직함
다소 손 waving에 가까운 전직 대학원생의 안락의자 논평이지만, 이 연구자들이 뛰어든 건 대단하고 저자들이 향후 작업에 Ghidra 통합을 언급한 걸 보면 방향은 맞아 보임 -
60억 모델이 330억 모델보다 잘하는 점이 흥미로움
330억 모델에 더 많은 학습 데이터가 필요하다는 뜻인지 궁금함
약 100만 개 C 프로그램으로 사전학습된 것과, 수조 토큰 규모로 학습된 DeepSeek-Coder를 비교하면 데이터 양이 몇 자릿수 차이남
LLM이 아닌 해법과 비교하면 어떤지도 궁금함- 이런 흐름은 LLM에서 한동안 이어져 왔음
대부분의 LLM은 크게 과소학습되어 있고, 70억 모델은 주류 모델 중 그나마 덜 과소학습된 편이라 LLM 미세조정 커뮤니티에서 많이 퍼졌음 - 330억 모델을 학습하기는 쉽지 않음
표준 방식 그대로 단순 미세조정하는 순진한 미세조정에서는 큰 모델 학습이 까다롭고, 데이터 양뿐 아니라 데이터 정제·학습률·감쇠 같은 모든 요소가 최종 성능에 영향을 줌 - 약 100만 개 C 프로그램과 2조 토큰을 그렇게 바로 비교할 수 있는지 의문임
그러려면 해당 C 프로그램의 평균 크기가 200만 토큰보다 몇 자릿수 작다고 가정해야 하는데, 실제로 그럴 수는 있어도 꽤 낙관적인 가정처럼 들림
- 이런 흐름은 LLM에서 한동안 이어져 왔음
-
성공한다면 컴파일러의 기계어를 1:1로 복제하는 셈인지 궁금함
그렇다면 완전한 코드가 잠재공간 안에 확률 분포로 존재할 수 있다는 뜻이 됨
아니면 더 가능성 높게는 논리만 복제한 뒤 대상 언어로 번역하는 형태일 수도 있음
컴파일에 비결정적 입력, 예를 들어 키나 해시가 필요한 바이너리는 깨질 것 같음
정말 흥미롭다 -
GPT-4가 비교에서 아직도 꽤 잘하는 게 놀라움
이 모델보다 컴파일 가능한 코드는 훨씬 잘 만들지만, 동작이 맞는 코드를 재현하는 정확도는 낮음
그래도 꽤 인상적임- GPT-4는 역컴파일에 직접 학습된 모델이 아닌데도 매우 인상적임
모델을 개선 중이니 업데이트를 계속 지켜봐 달라 - 이 방식이 C만큼 C++ 도 잘한다면 인상적일 텐데, 여기서는 그렇지 않음
- GPT-4는 역컴파일에 직접 학습된 모델이 아닌데도 매우 인상적임
{kind=link}