모든 개발자가 알아야 할 GPU 컴퓨팅
(codeconfessions.substack.com)- GPU는 낮은 단일 명령 지연보다 대규모 병렬 처리량을 우선하는 구조라서, 딥러닝·그래픽·수치 계산처럼 같은 종류의 연산을 대량으로 수행하는 작업에 강함
- CPU는 파이프라이닝, 비순차 실행, 추측 실행, 다단계 캐시로 순차 실행 지연을 줄이는 반면, GPU는 많은 ALU와 스레드로 지연을 감추며 처리량을 높임
- 32비트 정밀도 기준 Nvidia Ampere A100은 19.5 TFLOPS, 2021년 Intel 24코어 프로세서는 0.66 TFLOPS로, 수치 계산 처리량 격차가 계속 커지고 있음
- CUDA 커널은 CPU의 호스트 코드가 실행 준비를 맡고 GPU의 디바이스 코드가 grid·block·thread 구조로 실행되며, 스레드는 32개 단위의 warp로 묶여 SIMT 방식으로 처리됨
- 실제 성능은 SM의 레지스터, 공유 메모리, 블록 슬롯, 스레드 슬롯을 어떻게 나누는지에 크게 좌우되며, occupancy가 낮으면 지연을 숨기기 어렵고 최고 처리량에도 못 미칠 수 있음
CPU와 GPU의 설계 목표 차이
- CPU는 주로 순차 명령 실행을 빠르게 처리하도록 설계됨
- 명령 실행 지연을 줄이기 위해 instruction pipelining, out-of-order execution, speculative execution, multilevel cache 같은 기능을 사용함
- 두 숫자를 더하는 단일 연산이나 짧은 연산 흐름은 CPU가 GPU보다 낮은 지연으로 처리할 수 있음
- GPU는 대규모 병렬성과 높은 처리량을 중심으로 설계됨
- 비디오 게임, 그래픽, 수치 계산, 딥러닝처럼 많은 선형대수·수치 연산을 빠르게 수행해야 하는 작업이 이 구조에 잘 맞음
- 수백만·수십억 개의 같은 종류 연산에서는 GPU가 대규모 병렬성으로 CPU보다 훨씬 빠르게 처리할 수 있음
- 수치 계산 성능은 초당 부동소수점 연산 수인 FLOPS로 측정함
- Nvidia Ampere A100은 32비트 정밀도에서 19.5 TFLOPS 처리량을 제공함
- 2021년 기준 Intel 24코어 프로세서는 32비트 정밀도에서 0.66 TFLOPS 수준임
- GPU와 CPU의 처리량 격차는 해마다 커지고 있음
GPU가 지연을 숨기는 방식
- GPU는 개별 명령 지연이 높더라도 많은 스레드와 계산 자원을 활용해 지연 허용성을 확보함
- 어떤 스레드가 명령 결과를 기다리는 동안, GPU는 대기하지 않는 다른 스레드를 실행함
- 이 스케줄링 덕분에 계산 유닛이 가능한 한 계속 동작하며 높은 처리량을 유지할 수 있음
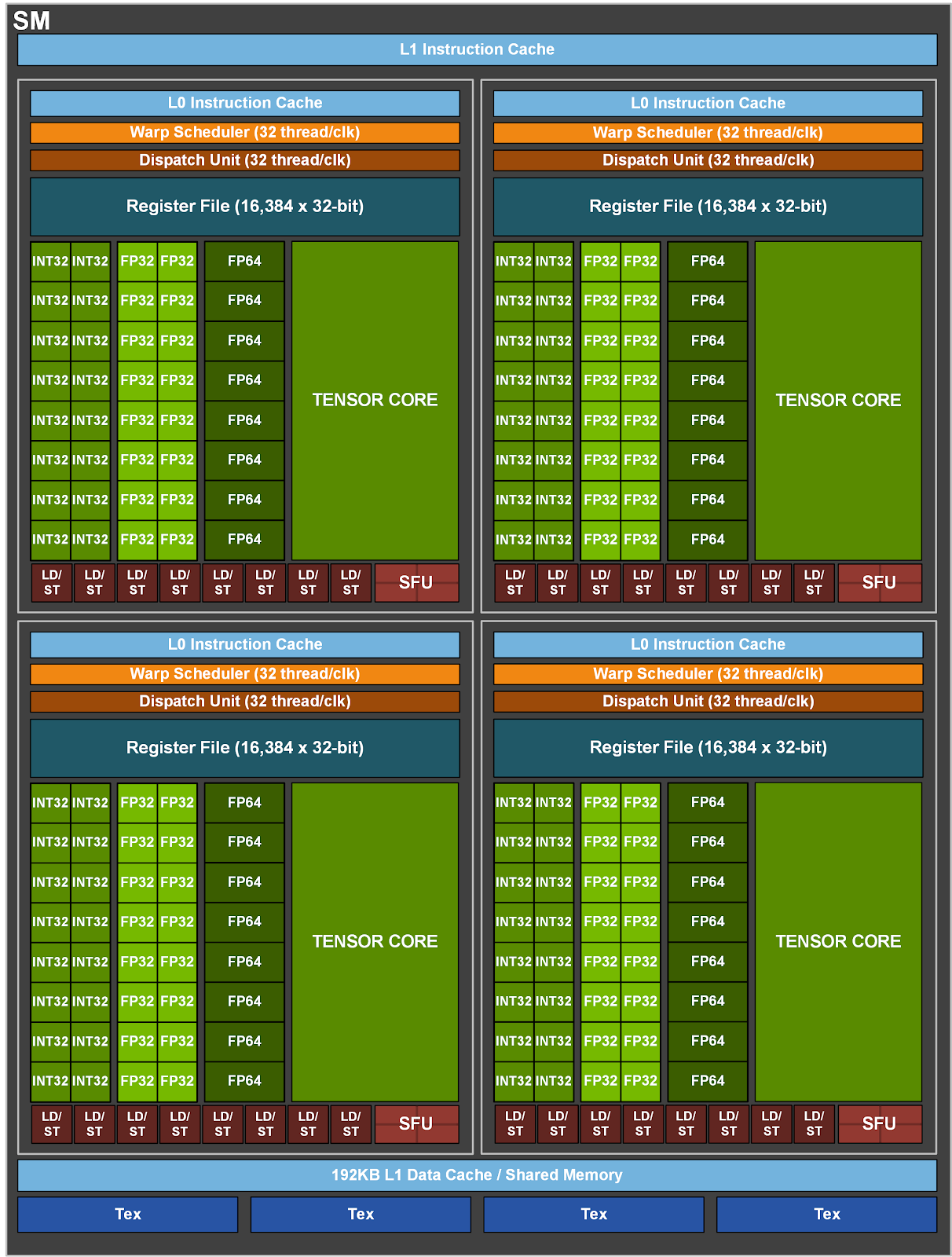
GPU 컴퓨트 아키텍처
- GPU는 여러 개의 스트리밍 멀티프로세서(SM) 배열로 구성됨
- 각 SM은 여러 streaming processor, core, thread를 포함함
- Nvidia H100은 132개 SM을 갖고, 각 SM에 64코어가 있어 총 8,448코어를 가짐
- 각 SM에는 모든 코어가 공유하는 제한된 온칩 메모리가 있음
- 이 메모리는 shared memory 또는 scratchpad로 불림
- SM의 제어 유닛 자원도 코어들이 함께 사용함
- 각 SM은 스레드 실행을 위한 하드웨어 기반 스레드 스케줄러를 갖춤
- 워크로드에 따라 tensor core, ray tracing unit 같은 특수 기능 유닛이나 가속 계산 유닛도 포함될 수 있음
GPU 메모리 계층
-
레지스터
- 각 SM에는 많은 수의 레지스터가 있음
- Nvidia A100과 H100은 SM당 65,536개 레지스터를 가짐
- 레지스터는 코어들이 공유하며, 스레드 요구에 따라 동적으로 할당됨
- 실행 중 특정 스레드에 할당된 레지스터는 해당 스레드 전용이라 다른 스레드가 읽거나 쓸 수 없음
-
constant cache
- SM에서 실행되는 코드가 사용하는 상수 데이터를 캐시함
- 프로그래머가 코드에서 객체를 명시적으로 상수로 선언해야 GPU가 constant cache에 보관할 수 있음
-
shared memory
- 각 SM에 있는 작고 빠른 저지연 온칩 프로그래머블 SRAM임
- 같은 SM에서 실행되는 스레드 블록이 공유함
- 여러 스레드가 같은 데이터 조각을 사용할 때 한 스레드만 global memory에서 읽고 나머지가 공유하면 중복 로드를 줄일 수 있음
- 스레드 블록 내부 스레드 간 동기화 메커니즘으로도 쓰임
-
L1 cache와 L2 cache
- 각 SM에는 L2 cache에서 자주 접근하는 데이터를 캐시하는 L1 cache가 있음
- L2 cache는 모든 SM이 공유하며, global memory에서 자주 접근하는 데이터를 캐시해 지연을 줄임
- L1과 L2 cache는 SM에 투명하게 동작하므로, SM 입장에서는 global memory에서 데이터를 받는 것처럼 보임
-
global memory
- GPU에는 오프칩 global memory가 있으며, 대용량·고대역폭 DRAM임
- Nvidia H100은 80GB HBM과 3000GB/s 대역폭을 가짐
- global memory는 SM에서 멀리 떨어져 있어 지연이 높지만, 온칩 메모리 계층과 많은 계산 유닛이 이 지연을 감추는 데 도움을 줌
CUDA 커널과 스레드 구조
- CUDA는 Nvidia GPU용 프로그램을 작성하는 프로그래밍 인터페이스임
- GPU에서 실행할 계산은 C/C++ 함수와 비슷한 형태의 커널(kernel) 로 표현됨
- 예시는 두 벡터를 입력으로 받아 원소별로 더하고 결과를 세 번째 벡터에 쓰는 벡터 덧셈 커널임
- 커널 실행 시 여러 스레드를 시작하며, 이 전체 묶음을 grid라고 부름
- grid는 하나 이상의 thread block으로 구성됨
- 각 thread block은 하나 이상의 thread로 구성됨
- 블록 수와 스레드 수는 데이터 크기와 원하는 병렬성에 따라 달라짐
- 256차원 벡터 덧셈에서는 스레드 256개짜리 블록 하나를 구성해 각 스레드가 벡터의 한 원소를 처리할 수 있음
- 더 큰 문제에서는 GPU의 사용 가능한 스레드 수가 부족할 수 있어, 각 스레드가 여러 데이터 포인트를 처리하게 할 수 있음
- CUDA 구현은 두 부분으로 나뉨
- host code는 CPU에서 실행되며 데이터 로드, GPU 메모리 할당, 설정된 스레드 grid로 커널 실행을 담당함
- device code는 GPU에서 실행되며 실제 커널 함수를 정의함
GPU에서 커널이 실행되는 단계
-
호스트에서 디바이스로 데이터 복사
- 커널 실행 전에 필요한 데이터를 CPU 메모리에서 GPU global memory로 복사해야 함
- 최신 GPU 하드웨어에서는 unified virtual memory를 사용해 host memory에서 직접 읽을 수도 있음
-
스레드 블록을 SM에 스케줄링
- GPU 메모리에 필요한 데이터가 준비되면 thread block을 SM에 배정함
- 한 블록 안의 모든 스레드는 같은 SM에서 동시에 처리됨
- GPU는 실행 전 해당 스레드에 필요한 SM 자원을 확보해야 함
- 실제로는 여러 thread block이 같은 SM에 동시에 배정될 수 있음
- SM 수는 제한되어 있고 큰 커널은 블록 수가 매우 많을 수 있으므로, 모든 블록이 즉시 실행되지는 않음
- GPU는 대기 중인 블록 목록을 유지하다가 어떤 블록이 끝나면 대기 블록 하나를 실행에 배정함
-
SIMT와 warp
- SM에 배정된 스레드는 다시 32개 단위로 묶이며, 이 묶음을 warp라고 부름
- 현재 세대 Nvidia GPU의 warp 크기는 32이지만, 향후 하드웨어에서는 바뀔 수 있음
- SM은 warp 안의 모든 스레드에 같은 명령을 가져와 발행함
- 스레드들은 같은 명령을 동시에 실행하지만 서로 다른 데이터 부분을 처리함
- 이 모델은 single instruction multiple threads(SIMT) 로 불리며, CPU의 SIMD 명령과 유사함
- Volta 이후의 최신 GPU에는 warp와 무관하게 스레드 간 전체 동시성을 허용하는 independent thread scheduling도 있음
-
warp 스케줄링과 지연 허용
- SM 안의 모든 processing block이 warp를 처리하더라도, 특정 순간에 실제로 명령을 실행하는 warp는 일부에 그침
- 이유는 SM의 실행 유닛 수가 제한되어 있기 때문임
- 어떤 warp가 오래 걸리는 명령 결과를 기다리면, SM은 그 warp를 대기 상태로 두고 기다릴 필요가 없는 다른 warp를 실행함
- 각 warp의 각 스레드는 자신만의 레지스터 집합을 갖기 때문에 warp 간 전환에는 별도 오버헤드가 없음
- CPU의 프로세스 컨텍스트 스위칭은 레지스터를 메인 메모리에 저장하고 다른 프로세스 상태를 복원해야 하므로 비용이 큼
-
결과 데이터를 디바이스에서 호스트로 복사
- 커널의 모든 스레드 실행이 끝나면 결과를 host memory로 다시 복사함
자원 분할과 occupancy
- GPU 자원 활용은 occupancy라는 지표로 측정함
- occupancy는 SM에 배정된 warp 수를 해당 SM이 지원할 수 있는 최대 warp 수로 나눈 비율임
- 최대 처리량을 위해서는 100% occupancy가 바람직하지만, 여러 제약 때문에 항상 가능하지는 않음
- SM에는 레지스터, shared memory, thread block slot, thread slot 같은 실행 자원이 고정되어 있음
- 이 자원은 스레드 요구사항과 GPU 한계에 따라 동적으로 나뉨
- Nvidia H100의 예시
- 각 SM은 32개 block, 64개 warp, 즉 2048개 thread를 처리할 수 있음
- block당 최대 1024개 thread를 지원함
- block 크기를 1024 thread로 실행하면 2048개 thread slot은 2개 block으로 나뉨
- 동적 분할은 고정 분할보다 계산 자원을 더 효율적으로 사용할 수 있음
- 고정 분할에서는 각 thread block이 고정량의 실행 자원을 받음
- 어떤 경우에는 스레드가 필요한 것보다 많은 자원을 배정받아 자원 낭비와 처리량 감소가 생길 수 있음
- occupancy를 낮추는 예시
- block 크기를 32 thread로 두고 총 2048 thread가 필요하면 64개 block이 생김
- 그러나 각 SM은 한 번에 32개 block만 처리할 수 있어 실제로는 1024 thread만 실행되고 occupancy는 50%가 됨
- SM당 레지스터가 65,536개일 때 2048 thread를 동시에 실행하려면 thread당 최대 32개 레지스터만 사용할 수 있음
- 커널이 thread당 64개 레지스터를 필요로 하면 SM당 1024 thread만 실행할 수 있어 occupancy는 다시 50%가 됨
- 낮은 occupancy는 지연을 충분히 감추지 못하게 만들고, 하드웨어의 최고 처리량에 도달하는 데 필요한 계산 처리량도 줄일 수 있음
- 효율적인 GPU 커널을 작성하려면 높은 occupancy를 유지하면서 지연을 줄이도록 자원을 신중히 배분해야 함
- 레지스터를 많이 쓰면 코드 자체는 빨라질 수 있지만 occupancy가 낮아질 수 있어 최적화 균형이 중요함
더 살펴볼 자료
- Programming Massively Parallel Processors: 4판이 최신 참고서이며 이전 판도 사용할 수 있음
- Programming Massively Parallel Processors: Prof. Hwu의 온라인 강의
- Nvidia’s CUDA C++ Programming Guide
- How GPU Computing Works
- GPU Programming: When, Why and How?
댓글과 토론
Hacker News 의견들
-
누군가 이 글에 대해 항의 메일을 보냈음: https://twitter.com/abhi9u/status/1715753871564476597
이는 HN 규칙 위반임. 실제로 사이트 가이드라인과 FAQ 양쪽에 모두 들어갈 만큼 중요한 유일한 항목이고, HN 사용자들은 이 문제에 매우 민감함
Q: 내 글에 추천을 부탁해도 되나?
A: 안 됨. 사용자는 누군가 홍보할 콘텐츠가 있어서가 아니라, 본인이 지적으로 흥미롭다고 느낄 때 투표해야 함. 이 규칙을 어기면 글, 계정, 사이트에 페널티를 주거나 차단하니 하지 말아야 함
https://news.ycombinator.com/newsfaq.html
추천, 댓글, 제출을 요청하지 말 것. 사용자는 홍보 목적이 아니라, 직접 마주친 무언가를 개인적으로 흥미롭다고 느낄 때 투표하고 댓글을 달아야 함
https://news.ycombinator.com/newsguidelines.html- 그 규칙을 몰랐고, 글을 올린 사람도 모르는 사람임
이제 알았으니 다시는 하지 않겠음
- 그 규칙을 몰랐고, 글을 올린 사람도 모르는 사람임
-
“호스트에서 장치로 데이터 복사” 부분에 비동기 복사가 없어서 놀랐음. GPU를 최대한 활용하려면 호스트와 GPU 사이에서 데이터를 복사하는 동안 GPU가 놀고 있으면 안 됨
많은 프레임워크가 비동기 작업 제출과 함께 실행될 수 있는 비동기 복사 예약 메커니즘을 제공함. 글 자체는 GPU 입문에 가깝지만, 실제 GPU 프로그래밍에서 비싼 GPU를 끝까지 짜내려면 그 너머에 온갖 요령과 기법이 있음. 요즘 최적화 대부분이 그렇듯 숨은 절벽과 비선형성이 많아서 프로파일링 도구가 큰 도움이 됨- 아마 64비트 부동소수점(double)을 쓸 텐데, 그렇다면 모든 GPU가 큰 도움이 되지는 않음. 특히 강한 CPU와 비교하면 더 그렇다
다만 FP64 유닛이 많은 GPU를 쓰면 크게 빨라질 수 있음. 보통 이런 건 게이밍 GPU가 아니지만, 4060이 그냥 있다면 FP64 성능이 약 300 GFLOPS라 CPU보다 높을 가능성이 큼. 현대 CPU도 이 영역에서 강력해서, 코어마다 클럭당 여러 FP64 연산을 발행할 수 있음
- 아마 64비트 부동소수점(double)을 쓸 텐데, 그렇다면 모든 GPU가 큰 도움이 되지는 않음. 특히 강한 CPU와 비교하면 더 그렇다
-
“대부분의 프로그래머는 CPU를 깊이 이해한다”라는 첫 문장이 너무 노골적으로 사실이 아니라서, 글이 훌륭할 수도 있겠지만 나머지를 진지하게 받아들이기 어려워짐
- 이렇게 바꿔 보면 어떨까: “상당수의 컴퓨터과학자, 컴퓨터공학자, 전기공학자, 취미 개발자는 …”
대학에서 재미로 철학 수업을 들었는데, 거기서 어떤 문장을 바로 버리지 않고 더 나은 형태로 고쳐 읽는 능력을 익혔음. 이제 뇌가 자동으로 과도한 일반화나 명백한 거짓도 합리적으로 가까운 참 명제로 번역함. 논지가 전개되면서 그 아이디어들을 재구성하고, 전체 글을 논리적으로 일관된 것으로 평가할 수 있게 됨
덕분에 형편없는 글을 읽어도 관심 있는 주제에 대한 새로운 참·거짓 전제와 주장이 남고, 그만큼 내 정신 세계가 넓어짐 - 대부분의 프로그래머에게는 확실히 사실이 아니지만, 저자가 CS 교육을 받은 엔지니어를 뜻했을 수는 있음. 정규 컴퓨터과학 과정을 거치면 CPU를 꽤 깊게 이해하게 되고, GPU는 훨씬 얕게 다루는 경우가 많음
- 인터넷의 글마다 “X에서 읽기를 멈췄다”식 댓글이 꼭 하나씩 붙는 이유를 모르겠음. 그런 말은 아무것도 보태지 않음
- 이 논쟁의 절반 이상은 깊이 이해한다를 어떻게 정의하느냐에 달려 있을 것 같음
대학에서 CPU 아키텍처의 기본 사실을 배웠고, 전반적인 지형을 아주 기초적으로 알고 있으며 가끔 제한된 지식의 업데이트를 접하지만, 그런 걸 “깊은 이해”라고 하지는 않겠음. 차라리 “CPU가 어떻게 동작하고 설계되고 사용되는지에 대한 기본 이해” 정도가 맞아 보임
어셈블리에 능숙하다면 저수준에서 CPU를 사용하는 법을 “깊이 이해한다”고 할 수 있을지도 모르지만, 그래도 좀 과장처럼 들림. CPU/GPU 설계 전문가라는 것과도 다름
그래서 동의함. 그래도 글은 흥미롭고, 특히 다이어그램이 좋음 - 학위 과정과 Structure and Interpretation of Computer Programs 수업에서 둘 다 배웠고, 저수준 컴퓨팅에 관심 있는 사람에게는 그 수업을 추천함
- 이렇게 바꿔 보면 어떨까: “상당수의 컴퓨터과학자, 컴퓨터공학자, 전기공학자, 취미 개발자는 …”
-
“실행 중 스레드에 할당된 레지스터는 그 스레드 전용이라 다른 스레드가 읽거나 쓸 수 없다”는 부분은 예외가 있음
HLSL의 wave intrinsic과 CUDA의 유사 기능은 현재 wavefront 안의 다른 스레드 레지스터를 읽을 수 있음. 또 메모리 아키텍처 단락에는 캐시가 같은 dispatch/grid 안의 스레드 사이에서 일관성을 보장하지 않지만, 칩 전체에 전역으로 존재하는 특수 기능 블록이 전역 메모리 원자 연산을 구현한다는 점도 넣을 만함 -
SIMD 프로그래밍은 정말 거칠다
화면의 모든 픽셀에 계산을 돌리고 싶다? 문제없음
분기 조건을 넣고 싶다? 아야- eval을 넣고 싶다? 전부 멈춤
- 공정하게 말하면 이건 말이 됨. 똑똑한 결정을 내리는 일은 단순 계산을 많은 작업자에게 확장하는 것보다 “더 어려움”
-
왜 아직도 GPU라고 부를까? PPU(병렬 처리 장치)가 더 나은 이름처럼 들림
- 범용 GPU 기능 말고도 그래픽스 전용 실리콘이 들어 있기 때문임
- GPU라고 하면 모두가 무슨 뜻인지 이해하기 때문임
drone과 quad-copter의 관계도 비슷함 - 벡터 처리 장치가 더 적절할 듯함
- CPU도 PPU임
- General Processing Unit
-
훌륭한 글임. 그리고 GPU는 자신이 하는 일에 관해서는 내가 떠올릴 수 있는 어떤 것보다 더 발전했고 성능도 좋음
하지만 SIMD는 더 유연한 다른 패러다임을 배우고 나면 꼭 필요하지 않은 범주에 넣고 싶음. 나는 MIMD와 클러스터/트랜스퓨터를 선호하는데, 2000년대쯤 사라진 것처럼 보임. 지금의 상태는 개발자에게 데이터를 직접 옮기고, 동시에 접근할 수 있는 메모리 위치 수에 대한 임의 제한 아래 셰이더를 쓰고, GPU/CPU용 언어를 따로 써서 작업을 중복하고, 광선 추적 같은 기능에 어떤 하드웨어가 있는지 알아야 하고, OpenGL/Metal/Vulkan 같은 주관 강한 프레임워크에 묶이도록 요구함. GPU는 내가 가고 싶은 곳으로 절대 데려다줄 수 없는 곁가지라서, 지난 25년은 잘못된 시간선에 사는 사람 같은 경험이었음
느슨하게 말하면, 무어의 법칙이 끝난 제약 안에서 확장 가능한 범용 CPU는 지역 메모리를 가진 멀티코어이며, 복사-시-쓰기 콘텐츠 주소화 메모리나 다른 캐싱 방식으로 데이터를 공유하고, 사용자가 데스크톱 컴퓨팅 환경에서 모든 계산 방식을 자유롭게 탐색할 수 있도록 단일 통합 주소 공간을 제공해야 함. 표준 어셈블리어를 쓰지만 보통 Erlang/Go, Octave/MATLAB, 이상적으로는 Julia 같은 함수형 프로그래밍 언어로 프로그래밍함. 3D 렌더링과 AI 라이브러리는 그 위의 계층이지 근본 요소가 아님
흥미롭게도 GPU가 내가 말한 멀티코어 구성에 대략 도달했지만, 드라이버가 범용 MIMD에 필요한 베어메탈 접근에서 사용자를 분리해 놓음. GPU 우위를 무너뜨릴 방법은 FPGA뿐이라고 생각했는데, 어쩌면 GPU 하드웨어를 통합 메모리를 가진 MIMD처럼 보이게 하는 드라이버를 쓸 기회가 있을 수도 있음. GPU 코어가 정수 연산을 얼마나 잘 처리하는지는 모르지만, 64비트 부동소수점의 32비트 정수 부분으로 근사할 수 있을 듯함. 그런 절충 때문에 MIMD 머신이 GPU보다 10~100배 느릴 수는 있어도 CPU보다는 10~100배 빠를 수 있음. 그러면서도 모바일 시장이 주도권을 잡으며 성능보다 가격과 전력 효율이 우선된 2007년쯤 이후 CPU를 정체시킨 대형 캐시와 빠른 버스에 과도하게 의존하지 않고 확장 가능함. MIMD 머신은 클러스터링해서 코드 변경 없이 SETI@home 같은 분산 계산 네트워크도 만들 수 있음. 일반 사용자에게 얼마나 힘이 될지 감을 잡자면, 데이터가 아니라 계산의 BitTorrent 대 FTP 비교와 비슷함 -
Apple Silicon 아키텍처가 NVIDIA와 어떻게 다른지 이해가 잘 안 됨
“Nvidia H100 GPU는 SM 132개, SM당 코어 64개로 총 8448코어”라는 문장을 보면 8448코어는 확실히 인상적임. 그런데 Apple M2 Ultra는 76코어뿐임?
어떻게 NVIDIA H100 GPU가 110배 넘게 많은 코어를 가질 수 있나? 분명 M2 Ultra보다 성능이 110배 높지는 않은데, 여기서 무슨 일이 벌어지는 건가?- 일반적으로 말하면 NVIDIA의 SM은 AMD GPU의 CU나 Apple GPU의 코어에 가장 가깝음. 여기서 “코어”는 개별 연산을 수행하는 SM의 하위 구성요소로 기억함
NVIDIA 블로그의 이 다이어그램 참고: https://developer-blogs.nvidia.com/wp-content/uploads/2021/g...
(https://developer.nvidia.com/blog/nvidia-ampere-architecture...) - NVIDIA가 사실상 벡터 레인인 것을 “코어”라고 부르고, SIMT의 “스레드”도 그런 벡터 레인 하나의 실행을 뜻하도록 쓰는 건 의도적으로 불명확하고 솔직히 부정직함
물론 레인마다 별도 프로그램 카운터를 지원한다는 점에서 그걸 “스레드”라고 부를 명분이 있다고 느끼겠지만, 결국 중요한 건 ALU의 속도와 처리량임 - H100은 방 하나를 데우는 데 쓸 수 있음. M2 Ultra보다 전력을 10배 넘게 먹음
- 일반적으로 말하면 NVIDIA의 SM은 AMD GPU의 CU나 Apple GPU의 코어에 가장 가깝음. 여기서 “코어”는 개별 연산을 수행하는 SM의 하위 구성요소로 기억함
-
이제 왜 머신러닝이 정밀도에 부동소수점을 쓰는지 이해했음. 선택이 아니라 그래픽스 코드가 그렇게 쓰기 때문이었음
“왜 머신러닝은 이렇게 비효율적인가” 퍼즐의 또 다른 조각임
실제 환경에서 메모리 복사 오버헤드가 어느 정도인지 궁금함. 보통 일처럼 동작한다면 아주 가혹할 것임. TCP 처리를 하드웨어로 넘겨서 그걸 피할 정도니까. 여기는 데이터가 훨씬 많지만, 더 큰 덩어리로 처리되기는 함- 현대의 큰 네트워크 상당수에서는 기울기 계산과 역전파의 GPU 계산 시간이 워낙 느려서, PCIe 버스로 부동소수점 데이터를 복사하는 게 병목이 아님
즉 부동소수점 이미지 미니배치를 복사하는 정도는 여전히 충분히 빠름. 기울기/SGD 반복이 느리고 계산량이 매우 크기 때문임. 혼합 정밀도를 써도 그렇다
얕은 네트워크에서는 원래의 압축 데이터만 GPU 메모리로 복사한 뒤, 압축 해제 등을 GPU에서 하는 이점이 있을 수 있음. 하지만 현대 GPU가 아직 PCIe 5를 채택하지 않은 건 원시 계산 성능이 더 중요하기 때문임
마지막으로 텐서 코어의 영향도 컸고, 네트워크에 따라서는 너무 빨라서 활용률이 매우 낮아질 수도 있음 - 부동소수점 숫자를 쓰는 선택이 특별히 비효율적이라고 보지는 않음. 프레임워크가 기본적으로 고정소수점이었다면 네트워크 전체에서 동적 범위를 맞추기가 까다로웠을 것임
학습 수학도 숫자가 연속적이라고 가정함 - 부동소수점은 더 크고, 그 연산도 더 어려움
다만 CPU 기반 LLM이 왜 양자화를 하는지 궁금했음. 이해하기로는 가중치 정밀도를 낮춰 메모리를 덜 쓰는 과정임
정밀도 부족이 차이를 만드는지는 불분명함. 그렇다면 왜 애초에 부동소수점을 쓰는가? 정밀도가 중요하지 않다면 추가 정밀도는 실제 이유 없이 자원을 더 쓰게 만들 뿐이고, 아마 필요한 것보다 몇 자릿수나 더 많은 자원을 쓸 가능성이 큼
이 분야는 성능을 이해한 사람들이 시작한 게 아니었음. 도구를 사용해 무언가를 만들었지만 “왜”는 없음. 도구가 그렇게 하니까 그렇게 한 것임
이게 중요한 이유는 이렇다. 일반 CPU에서도 데이터에 접근하는 방식 하나가 다른 방식보다 몇 자릿수 빠를 수 있지만, 그걸 알고 있어야 함. LLM 비용을 몇 자릿수 줄이고 싶지 않은가? - 부동소수점의 무엇이 비효율적인가? 머신러닝은 여러 자릿수 규모의 동적 범위에 접근할 수 있다는 점에서 큰 이득을 얻는 것처럼 보임
- 현대의 큰 네트워크 상당수에서는 기울기 계산과 역전파의 GPU 계산 시간이 워낙 느려서, PCIe 버스로 부동소수점 데이터를 복사하는 게 병목이 아님
-
몇 년 전 CPU와 GPU의 까다로운 부분을 다룬 이 발표와 슬라이드도 볼 만함
Alexander Titov — Know your hardware: CPU memory hierarchy https://youtu.be/QOJ2hsop6hM
https://github.com/alexander-titov/public/blob/master/confer...
Know Your Hardware - CPU Memory Hierarchy -- Alexander Titov -- C%2B%2B Moscow Meetup March 2019.pdf
https://github.com/alexander-titov/public/blob/master/confer...
GPGPU - what it is and why you should care -- Alexander Titov -- CoreHard 2019.pdf
{kind=link}