더 적은 학습 데이터와 작은 모델로 더 큰 언어 모델을 능가하는 기술
(blog.research.google)- 대형 LLM은 few-shot만으로 새 작업을 풀 수 있지만 서빙 비용이 커서, Google Cloud AI 팀은 작은 작업 특화 모델에 자연어 근거(rationale) 를 함께 학습시키는 distilling step-by-step을 제안함
- 이 방식은 few-shot Chain-of-Thought(CoT) 로 LLM의 중간 추론을 뽑아, T5 모델이 라벨 예측과 근거 생성을 함께 배우는 멀티태스크 학습으로 전환함
- 실험은 540B PaLM을 기준 LLM으로, T5를 다운스트림 모델로 사용해 e-SNLI, ANLI, CQA, SVAMP의 자연어 추론·상식 질의응답·산술 문장제 문제를 평가함
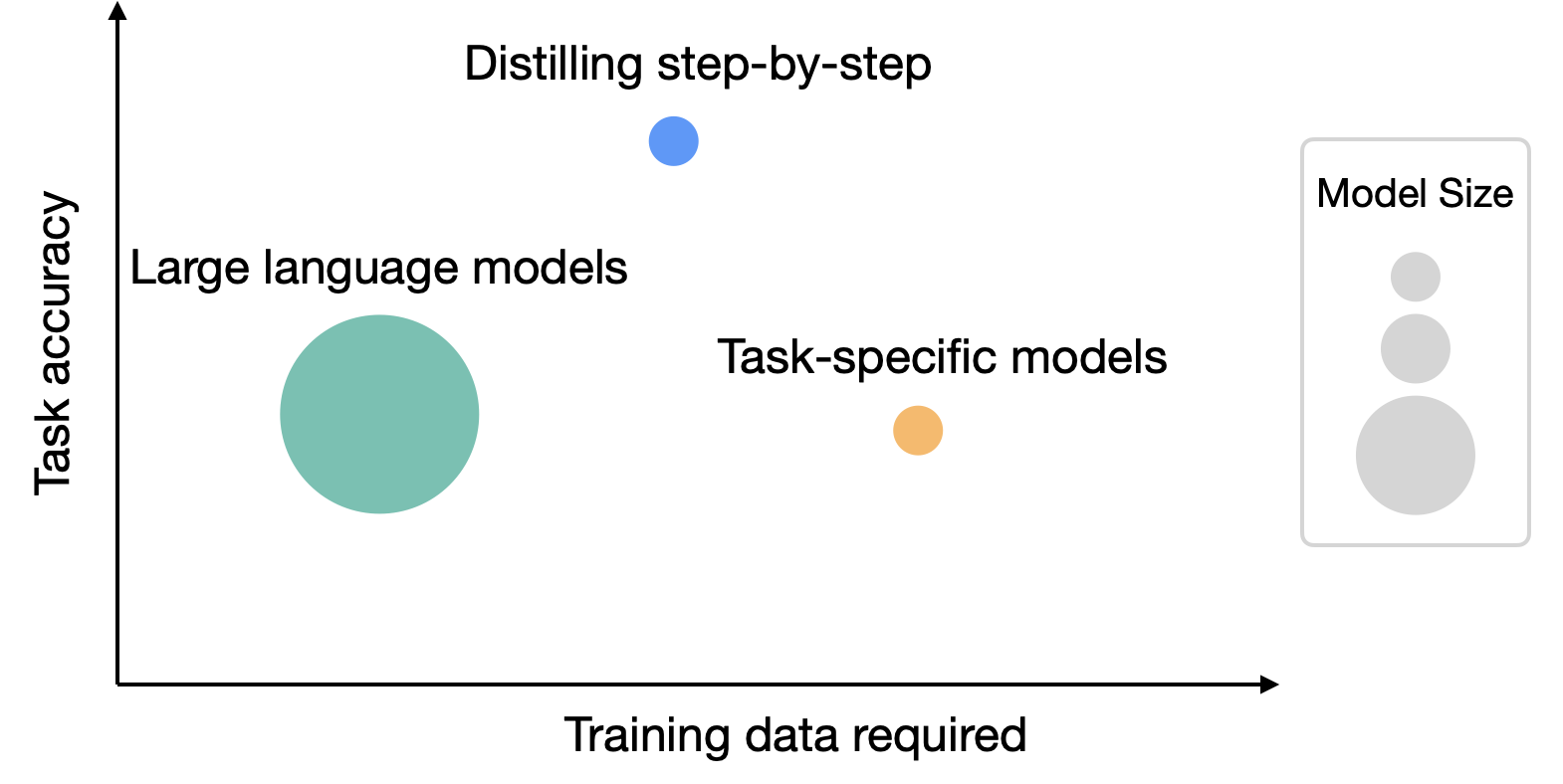
- e-SNLI에서는 전체 데이터의 12.5% 만으로 표준 미세조정보다 좋은 성능을 냈고, ANLI에서는 770M T5가 80% 데이터로 540B PaLM few-shot 성능을 넘으며 모델 크기를 700배 이상 줄임
- 작은 모델 배포와 학습 데이터 수집 비용 사이의 절충을 줄이는 접근이며, Vertex AI에서 private preview로 제공됨
LLM 배포 비용과 작은 모델 학습의 한계
- LLM은 zero-shot과 few-shot 프롬프팅으로 보지 못한 새 작업을 처리할 수 있지만, 실제 서비스에서는 모델 크기가 큰 제약이 됨
- 175B 규모 LLM 하나를 서빙하려면 특수 인프라에서 최소 350GB GPU 메모리가 필요함
- 당시 최신 LLM은 500B 파라미터를 넘는 규모로 구성됨
- 실무에서는 더 작은 작업 특화 모델을 배포하는 경우가 많고, 보통 두 가지 방식이 쓰임
- 미세조정(fine-tuning): BERT나 T5 같은 사전학습 소형 모델을 사람이 라벨링한 다운스트림 데이터로 업데이트함
- 증류(distillation): 더 큰 LLM이 생성한 라벨로 소형 모델을 학습함
- 두 방식 모두 비용 부담이 남아 있음
- 미세조정은 사람이 만든 라벨이 필요해 비용과 작업량이 큼
- 증류는 많은 양의 비라벨 데이터가 필요하며, 이 데이터도 수집하기 어려울 수 있음
Distilling step-by-step의 핵심 아이디어
- Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes는 모델 크기와 학습 데이터 수집 비용 사이의 절충을 줄이려는 방법임
- distilling step-by-step은 LLM에서 자연어 근거, 즉 중간 추론 단계를 추출해 작은 모델 학습의 추가 감독 신호로 사용함
- 자연어 근거는 입력 질문과 출력 답 사이의 연결을 드러냄
- 예를 들어 방의 길이와 너비, 이미 가진 카펫 면적이 주어졌을 때 LLM은 “Area = length * width” 같은 중간 근거를 생성할 수 있음
- 이런 근거에는 작은 모델이 원래 많은 데이터로 배워야 할 수 있는 작업 지식이 포함될 수 있음
- 라벨만 학습하는 대신 라벨과 근거를 함께 학습해 작은 모델이 더 적은 데이터로 작업을 익히도록 함
두 단계 학습 절차
- 첫 단계는 few-shot CoT 프롬프팅으로 LLM에서 근거를 추출하는 과정임
- 작업별로 입력, 근거, 출력의 세 요소로 구성된 예시를 LLM 프롬프트에 넣음
- LLM은 이 예시를 따라 새로운 입력에 대한 근거를 생성함
- 상식 질의응답 예시에서는 “Sammy wanted to go to where the people are”라는 질문과 선택지가 주어짐
- 정답은 “(a) populated areas”임
- 근거는 “많은 사람이 있는 장소여야 하며, 선택지 중 populated areas만 많은 사람이 있는 곳”이라는 연결을 제공함
- 두 번째 단계에서는 추출된 근거를 작은 모델 학습에 넣음
- 표준 라벨 예측 작업에 더해 새로운 근거 생성 작업을 학습함
- 모델 입력 앞에
[label]또는[rationale]같은 작업 접두어를 붙여 두 작업을 구분함 - 근거 생성 작업은 모델이 중간 추론 단계를 만들도록 학습시키고, 결과적으로 라벨 예측을 더 잘 하도록 유도함
실험 설정과 비교 대상
- 기준 LLM은 540B PaLM임
- 작업 특화 다운스트림 모델에는 T5 모델을 사용함
- CoT 프롬프팅은 가능한 경우 기존 CoT 프롬프트를 사용하고, 새로운 데이터셋에는 직접 예시를 구성함
- 평가는 3개 NLP 작업에 걸친 4개 벤치마크로 진행됨
- 비교 기준은 두 갈래임
- few-shot 프롬프트 LLM과 비교하기 위해 540B PaLM의 few-shot CoT 프롬프팅을 사용함
- 표준 미세조정과 표준 증류도 비교 대상에 포함되며, 블로그 본문은 표준 미세조정 비교를 중심으로 다룸
더 적은 학습 데이터로 표준 미세조정을 넘음
- distilling step-by-step은 표준 미세조정보다 훨씬 적은 학습 데이터로 더 좋은 성능을 냄
- e-SNLI에서는 전체 데이터셋의 12.5% 만 사용해 전체 데이터로 학습한 표준 미세조정보다 나은 성능을 달성함
- 다른 데이터셋에서도 필요한 데이터 크기가 줄어듦
- ANLI: 75% 데이터셋 크기 감소
- CQA: 25% 데이터셋 크기 감소
- SVAMP: 20% 데이터셋 크기 감소
- 이 비교는 다양한 크기의 사람이 라벨링한 데이터셋에서 220M T5 모델을 사용해 수행됨
더 작은 배포 모델로 PaLM 기준을 넘음
- distilling step-by-step은 few-shot CoT 프롬프트를 사용한 LLM보다 훨씬 작은 모델로 더 좋은 성능을 냄
- e-SNLI에서는 220M T5 모델로 540B PaLM보다 좋은 성능을 달성함
- ANLI에서는 770M T5 모델로 540B PaLM보다 좋은 성능을 냄
- 이 모델은 PaLM보다 700배 이상 작음
- 같은 770M T5 모델은 표준 미세조정만으로는 PaLM 성능에 도달하기 어려움
- 작은 모델 크기와 LLM 기준 성능 초과를 동시에 보여주는 결과임
데이터와 모델 크기를 동시에 줄인 결과
- ANLI에서 distilling step-by-step은 770M T5와 전체 데이터의 80% 만으로 540B PaLM의 few-shot 성능을 넘음
- 같은 조건에서 표준 미세조정은 전체 데이터의 100% 를 사용해도 PaLM 성능을 따라잡지 못함
- 거친 탐색을 통해 LLM의 few-shot CoT 성능을 넘는 데 필요한 최소 T5 모델 크기와 최소 사람 라벨 예시 수를 확인함
- 결과적으로 이 방식은 LLM 성능을 넘기 위해 필요한 배포 모델 크기와 학습 데이터 양을 동시에 줄임
제공 형태
- distilling step-by-step은 Vertex AI에서 private preview로 제공됨
- 사용을 원하는 경우 Google Cloud Project 번호와 사용 사례 요약을 포함해
vertex-llm-tuning-preview@google.com으로 연락하도록 안내됨
댓글과 토론
Hacker News 의견들
-
더 작은 전문가 모델이 대부분의 애플리케이션을 지배할 것 같음. 크기와 사용성 사이에는 최적점과 미묘한 균형이 있고, 글에서 보여준 것 같은 여러 메커니즘이 그 최적점을 찾아 실현하게 될 듯함
- 큰 범용 모델은 여러 개의 작은 전문가 모델과, 어떤 도메인 특화 모델에 물어볼지 결정하는 중계 모델로 구성하면 됨
-
증류 모델에 T5를 쓴 점이 흥미로움. 인코더-디코더 구조는 사라지는 흐름이라고 생각했는데, 아직도 관련성이 있는 듯함
또 이 아이디어가 상상도 못 할 정도로 기발하거나 틀을 벗어난 것도 아니라는 점도 흥미로움. 아직 탐색할 낮은 과일이 많이 남아 있고, 대규모 언어 모델의 미래도 정해진 게 아님을 보여줌. 진짜 해법은 이런 방식으로 훈련된 전문가 혼합일 수도 있음. 올바른 아이디어 조합만 찾으면 성배에 가까운 목표가 달성 가능해 보인다는 점이 신남- T5 계열은 훌륭함. FastChat-T5는 텍스트 생성 품질이 놀랍고, 예를 들어 검색 증강 생성 챗봇에도 좋으며, CPU에서도 실시간 대화가 가능할 만큼 빠르게 돌릴 수 있음
- 언급된 논문은 5월에 제출된 것임. 인코더-디코더 구조는 멀티모달 모델에서는 여전히 꽤 타당해 보임
아직 낮은 과일이 많이 남아 있음. 사고 사슬, 사고 트리, 사고 그래프, self-ask, self-critique, self-plan, self-reflect 등 수십 가지 변형을 본 것 같음 - 왜 인코더-디코더 구조가 사라지는 흐름이라고 생각했는지 궁금함
-
대규모 언어 모델/기계학습/인공지능 분야의 활동량과 진전은 정말 대단함. 특히 Nvidia 같은 하드웨어가 매우 비싼 상황에서는 이런 최적화가 특히 가치 있음
-
이건 https://arxiv.org/abs/2212.08410와 같은 내용인데 1년 뒤에 나온 것 아닌가
- 개선 폭은 인상적이지만, GSM8K 22% 는 최종 결과로는 시선을 끌기 어렵긴 함
-
연구자는 아니지만, 가장 효과적인 모델은 멀티모달이고 핵심 커리큘럼을 신중하게 설계해 훈련한 모델일 것이라는 직관이 항상 있었음
시스템이 효과적이고 정확하게 일반화하는 데 필요한 기본 구조와 기술을 습득하고 유지하도록 보장하고 싶음. 그런 것들을 유지하면서 다양한 데이터를 많이 먹여 예외와 기술 조합 방식을 배우게 하는 식임. 다만 핵심 기술과 지식을 끝까지 보장할 방법이 필요함. 논문에서 하는 것처럼 최종 답뿐 아니라 그 이해나 조작 과정도 출력하게 하면 가능할지도 모름
예를 들어 코드 생성 모델이라면 요청된 프로그램의 상태 기계 시뮬레이션을 출력하도록 요구할 수 있음- 멀티모달이 갈 길이라는 데는 동의하지만, 커리큘럼을 꼭 신중하게 설계해야 한다고 기대할 이유는 전혀 직관적이지 않음. https://gwern.net/scaling-hypothesis와 비교해볼 만함
- 학교 커리큘럼이라는 아이디어를 생각해보면, 훈련 데이터의 순서가 차이를 만들지 궁금함. 단순한 것에서 복잡한 것으로 먹이느냐, 그 반대로 먹이느냐에 따라 달라질 수 있음. 경사 하강법은 분명 더 좋거나 나쁜 다른 국소 최솟값에 도달할 수 있지 않을까
-
첫 번째 그림에서 왜 대규모 언어 모델의 훈련 데이터 양이 증류 모델과 작업 특화 모델보다 적은지 궁금함
아니면 저자들이 대규모 언어 모델에 필요한 훈련 데이터 양을 증류/작업 특화 모델에 필요한 훈련 데이터에 포함해서 계산한 건가
https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEj...- 맞음. 문제를 해결하기 위해 직접 수집해야 하는 데이터 양을 세고 있음
사전 훈련된 대규모 언어 모델을 가져올 수 있고, 그 경우 내가 수집해야 하는 데이터는 그 모델을 미세 조정하는 데 필요한 데이터임
- 맞음. 문제를 해결하기 위해 직접 수집해야 하는 데이터 양을 세고 있음
-
저 거대한 대규모 언어 모델들에는 쓰이지 않는 용량이 많이 남아 있는 건가, 아니면 작은 언어 모델이 추론 작업을 그냥 흉내 내는 건가? 흉내 내기를 흉내 내는 셈인가?
- 실제와 흉내 사이에는 본질적인 구분이 없음
거대한 대규모 언어 모델이 훈련되는 데이터셋에는 진전을 방해하는 잡음이 많음. 또 관련 없는 지식도 많이 들어 있어서 모델이 그것까지 배우거나 암기해야 하고, 그래서 터무니없이 많은 매개변수가 필요해짐
언어 모델에 인간 지식의 총합을 가르치려는 게 아니고 고품질로 선별된 데이터셋을 제공한다면, 규모 장벽은 훨씬 낮아짐
https://arxiv.org/abs/2305.07759 - 그 질문은 “현재의 거대한 대규모 언어 모델들이 최적에 가까운가”와 거의 같은 뜻으로 보이는데, 그렇지 않다는 건 명백해 보임
최적 크기를 추정할 방법에 대해 어떤 아이디어가 있을지 궁금함 - 큰 모델은 일반화를 더 잘함. 작은 모델은 특정 작업에 맞춰 훈련하기가 더 쉬움
- 실제와 흉내 사이에는 본질적인 구분이 없음
-
흥미로움. 작은 모델이 최신 대규모 언어 모델과 비슷한 성능을 내려면 RLHF가 필수일까? 출력 구조, 어조, 도메인 이해와 관련된 문제는 지시 튜닝으로 해결될 것 같은데, 작은 모델의 추론 능력을 향상시키기에도 충분할지는 모르겠음
-
1,750억 매개변수짜리 대규모 언어 모델 하나를 서비스하려면 특수 인프라에서 최소 350GB GPU 메모리가 필요하다고 함
Apple은 사용 가능한 GPU 메모리를 최대 144GB까지 지원하는 Mac Studio를 판매하고 있음
만약 300GB 이상을 탑재한 Mac Pro를 내놓고 대규모 언어 모델 서빙 시장을 장악한다면 꽤 재미있을 듯함- Metal에서 대규모 언어 모델을 배치 처리할 수 있는 프레임워크가 있나? GGML이나 MLC에는 아직 없는 것 같음
그렇지 않다면 지금 시점에서 대규모 언어 모델 호스팅에 적합하지 않은 또 다른 이유일 뿐임
어쨌든 진짜 판을 흔들 수 있는 쪽은 Intel임. 이론적으로 2x48GB Arc 카드를 들고 들어와, AMD/Nvidia가 전문가용 카드 고객 때문에 뛰어들지 않는 시장을 더 낮은 가격으로 공략할 수 있음 - Apple의 하드웨어 장점이 M3 세대에서 제대로 풀리길 기대함. A17 Pro에 레이 트레이싱 지원이 들어간 걸 보면 기존 강자들을 빠르게 따라잡을 수 있겠다는 희망이 생김
솔직히 그게 최신 Apple 하드웨어를 피하게 만든 유일한 이유임. 주로 책상에서 컴퓨터를 쓰고, PC 하드웨어는 특히 GPU가 Apple 최고 제품이 할 수 있는 것보다 훨씬 앞서 있음. 업무에 Linux가 아주 잘 맞고, 일이 끝나면 게임도 할 수 있는데 거의 4천 달러를 쓰는 건 정당화하기 어려움 - 대규모 언어 모델 사용자층을 잡기 위해 누가 먼저 하드웨어 제품의 RAM 용량을 극적으로 늘릴지 궁금함. 시장 점유율을 얻는 길처럼 보임
- 저 숫자는 양자화도 적용하지 않은 값임. 1,750억 매개변수를 4비트로 양자화하면 약 120GB VRAM에 들어갈 것임. 340억 매개변수 모델은 4비트 양자화로 RTX3090 24GB VRAM 한 장에도 들어감
- Metal에서 대규모 언어 모델을 배치 처리할 수 있는 프레임워크가 있나? GGML이나 MLC에는 아직 없는 것 같음
-
Facebook이 모든 사용자의 전체 채팅 기록으로 대규모 언어 모델을 훈련할 수 있을지 궁금함
{kind=link}