Mistral OCR 4 공개
(mistral.ai)- Mistral AI가 공개한 Mistral OCR 4는 문서에서 텍스트만 뽑는 OCR을 넘어 바운딩 박스, 블록 분류, 인라인 신뢰도 점수까지 함께 반환하는 문서 이해 모델임
- 10개 언어 그룹의 170개 언어와 단일 컨테이너 자체 호스팅을 지원해, 데이터 주권·컴플라이언스가 중요한 조직의 문서 수집 파이프라인에 맞음
- 사람 선호도 평가에서는 평균 72% 승률을 기록했고, OlmOCRBench 85.20, OmniDocBench 93.07 등 공개·내부 평가에서도 높은 점수를 냄
- 다만 정답 오류, 동등한 수식 표기, 다중 컬럼 읽기 순서, 헤더·푸터 처리 같은 채점 한계 때문에 벤치마크 점수는 실제 문서 평가와 함께 봐야 함
- API는 1,000페이지당 $4, Batch API는 $2, Document AI는 $5이며, 원시 추출은 OCR 4로 충분하지만 구조화 JSON·이미지 주석·커스텀 프롬프트가 필요하면 Document AI 경로가 맞음
OCR 4가 반환하는 구조화 문서 표현
- OCR 4는 다양한 문서의 콘텐츠를 추출하고 구조화하며, 이전 세대처럼 깨끗한 텍스트와 표 변환에만 머물지 않고 구조화 표현을 함께 제공함
- 각 블록에는 바운딩 박스, 블록 유형, 페이지·단어 단위 인라인 신뢰도 점수가 포함됨
- 다운스트림 시스템은 문서의 내용뿐 아니라 각 요소의 위치, 역할, 신뢰 수준까지 활용할 수 있음
- 주요 활용 흐름은 다음과 같음
- RAG용 의미 단위 청킹: 정리되고 분류된 블록을 검색 단위로 사용
- 에이전트용 구조 프리미티브: 양식 작성, 청구서 처리, 컴플라이언스 점검 지원
- 커넥터용 구조화 콘텐츠: 수집·인덱싱 파이프라인에 일관된 타입 출력 제공
형식, 언어, 배포 방식
- 입력 형식은 PDF, DOC, PPT, OpenDocument 같은 일반적인 엔터프라이즈 문서 형식을 포함함
- 10개 언어 그룹의 170개 언어를 지원하며, 여러 시스템이 약해지는 전문·저자원 언어도 범위에 들어감
- 모델은 단일 컨테이너에 배포할 수 있을 만큼 작아 비용 민감형·고처리량 환경에 적합함
- 완전한 자체 호스팅 실행을 지원하므로 데이터 주권 요구가 있는 조직은 문서 데이터를 자체 인프라 안에 유지할 수 있음
- 자체 관리형 배포는 엔터프라이즈 고객에게 제공됨
가격과 사용 경로
- 개발자는 API로 모델을 통합할 수 있고, 팀은 Mistral Studio의 Document AI를 통해 같은 엔진을 노코드 애플리케이션 방식으로 사용할 수 있음
- 가격은 다음과 같음
- OCR 4 API: 1,000페이지당 $4
- Batch API 50% 할인 적용 시: 1,000페이지당 $2
- Document AI: 1,000페이지당 $5
- OCR 4는 Mistral Search Toolkit의 수집 컴포넌트로 통합되어 RAG와 엔터프라이즈 검색용 수집·검색·평가 워크플로에 인용 가능한 입력을 제공함
평가 결과와 벤치마크 한계
- OCR 4 평가는 AI 네이티브 OCR 모델, 범용 프런티어 모델, 엔터프라이즈 문서 서비스, Mistral OCR 3와의 비교로 진행됨
- 사람 선호도 평가는 실제 사용을 반영하도록 12개 이상 언어의 600개 이상 문서를 구성하고, 독립 주석자가 각 경쟁 시스템 출력과 OCR 4 출력을 문서별로 블라인드 비교함
- 주석자는 테스트된 모든 시스템에 대해 대부분의 문서에서 OCR 4를 더 선호함
- 평균 승률은 72% 임
- 공개 OlmOCRBench에서는 테스트된 모델 중 최고 전체 점수인 85.20을 기록함
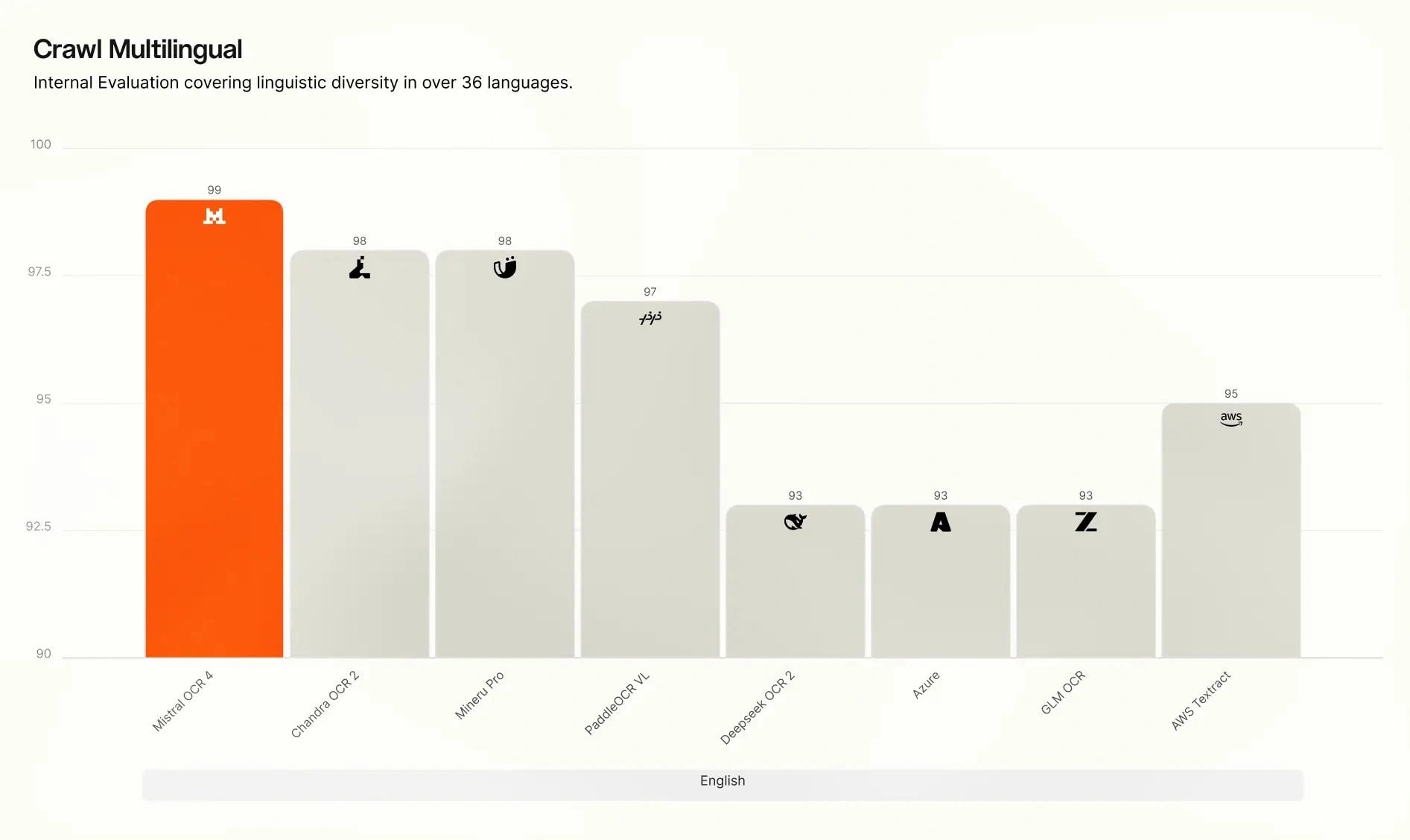
- 내부 Crawl Multilingual evaluation에서는 .98로 AI 네이티브·엔터프라이즈 솔루션보다 앞섬
- OmniDocBench 점수는 93.07이지만, OlmOCRBench와 OmniDocBench 모두 일부 출력 채점 방식에 알려진 한계가 있음
- 감사된 불일치의 다수는 모델 오류라기보다 벤치마크 비교 방식에서 발생함
- 정답 오류: 참조 주석에 누락·추가 텍스트, 가려진 영역의 전사, 오타가 포함될 수 있음
- 동등한 수식 표기: 렌더링 결과가 같은 LaTeX라도 문자열이 다르면 불일치로 계산됨
- 수식 분할: 하나의 수식으로 내보내는지 여러 인라인 조각으로 나누는지에 따라 정답 매칭이 흔들림
- 다중 컬럼 읽기 순서: 컬럼 경계에서 나뉜 단어와 컬럼 순서 가정 때문에 올바른 추출도 실패로 채점될 수 있음
- 블록 유형 귀속: 헤더·푸터를 출력에서 제거한 뒤에도 페이지 제목 같은 문자열을 테스트가 잘못 플래그할 수 있음
- 이런 산물은 수학, 과학, 다중 컬럼 문서에 집중되며, 잘못된 출력에 보상을 주기보다 올바른 출력을 더 자주 벌점 처리함
- 모든 경쟁사 점수는 내부 재현 결과이므로, 실제 도입 전에는 자체 문서로 직접 평가하는 편이 안전함
다국어 성능
- 내부 다국어 평가에서 OCR 4는 8개 언어 그룹 모두에서 앞섬
- English
- Western Europe
- Eastern Europe
- Middle Eastern
- Chinese
- East Asian
- Southeast Asian
- Hindi, Japanese, Georgian, Bengali, Armenian, Hebrew, Greek, Gujarati, Tamil, Malayalam, Kannada, Telugu 등 전문 언어
- 격차는 전문·저자원 언어에서 가장 컸으며, 여러 경쟁 시스템이 급격히 저하되는 영역에서도 OCR 4는 높은 정확도를 유지함
권장 사용 사례와 제외 범위
- OCR 4는 고처리량 파이프라인과 대화형 문서 워크플로를 모두 지원함
- 권장 사용 사례는 다음과 같음
- 복잡한 다국어 문서의 문서 파싱·추출
- RAG용 구조화·분류·인용 가능 콘텐츠 생성
- Search Toolkit과 결합한 검색 파이프라인 입력
- 양식 작성, 청구서 처리, 컴플라이언스 점검 같은 에이전트 워크플로
- 신뢰도 점수를 활용한 사람 검증 기반 구조화 데이터 파이프라인
- 엔터프라이즈 검색과 지식 베이스용 데이터 소스 컴포넌트
- 초기 사용자는 OCR 4를 청구서의 구조화 필드 변환, 회사 아카이브 디지털화, 기술·과학 보고서의 깨끗한 텍스트 추출, 엔터프라이즈 검색에 적용하고 있음
- OCR 4는 문서 이해 모델이며 의사결정자가 아님
- 의료 진단, 법률 조언이나 판단, 고위험 금융 결정, 안전 중요 시스템, 실시간·지연 민감 처리, 원시 오디오·비디오 같은 비문서 입력에는 의도되지 않음
OCR 4 API와 Document AI 선택 기준
- OCR 4는 단일 API 엔드포인트로 제공되며, 모든 요청은 같은 기본 OCR 모델을 실행함
- 기본 응답에는 항상 추출 콘텐츠, 바운딩 박스, 블록 유형, 신뢰도 점수, Markdown 구조 텍스트가 포함됨
- 순수 추출 모드는 다음 상황에 맞음
- 빠르고 정확한 문서 추출을 애플리케이션, 에이전트, 데이터 파이프라인에 직접 내장
- 원시 응답, 바운딩 박스, 블록 유형, 신뢰도 점수를 직접 사용해 커스텀 후처리 로직 구성
- Batch API로 처리량과 비용을 제어하는 고처리량·배치 수집
- 엄격한 데이터 프라이버시, 주권, 컴플라이언스 요구에 맞춘 자체 호스팅
- Document AI 기능은 같은 엔드포인트에 추가 매개변수를 넣어 활성화함
- 문서와 함께 JSON 스키마를 전달하면 OCR 출력이
mistral-small-2603에 입력되어 지정한 명세에 맞는 구조화 JSON을 생성함 - 이미지 주석 스키마를 전달하면 감지된 이미지마다 추가 비전-언어 모델 호출로 구조화 JSON을 생성함
- JSON 스키마와 함께 커스텀 프롬프트를 사용해 전체 문서의 추출 콘텐츠 해석이나 요약을 안내할 수 있음
- 비즈니스 사용자, 솔루션 팀, 파일럿 프로젝트가 별도 후처리 파싱 로직 없이 구조화 결과를 만들 수 있음
- 문서와 함께 JSON 스키마를 전달하면 OCR 출력이
- 원시 추출 콘텐츠가 필요하면 OCR 4를 그대로 쓰고, 구조화 형식 재가공·도메인 필드 주석·커스텀 지시 처리가 필요하면 Document AI 매개변수를 추가함
제공 채널과 시작 방법
- Mistral OCRv4와 OCRv4 기반 Document AI는 API, Mistral Studio, Amazon SageMaker, Microsoft Foundry에서 사용할 수 있음
- Snowflake Parse Document 지원은 곧 제공될 예정임
- 민감한 정보를 자체 인프라 안에 유지해야 하는 조직을 위해 OCR 4는 자체 호스팅 옵션도 제공함
- 시작 리소스는 다음과 같음
- Getting Started with OCR 4 Cookbook: 첫 추출, 바운딩 박스 작업, 블록 분류를 다룸
- OCR4 in Production webinar: 7월 7일 오후 6시 CET에 데모와 Q&A 진행
- Contact Sales: 추가 정보 문의
댓글과 토론
Hacker News 의견들
-
US Postal Service는 늘 기술적 경이처럼 느껴짐
훨씬 원시적인 기술로도 수십억 통의 우편물을 식별하고 라우팅하는 데다, 미국 주소는 말도 안 되게 비표준적이라 같은 주소를 여러 방식으로 써도 같은 곳에 도착하곤 함
이 분야에 공개된 지식도 많겠지만, USPS 규모로 수년간 해낸 일이라면 OCR 발표를 볼 때마다 이미 풀린 문제처럼 보임- 아버지는 한때 알제리에서 온 편지를 받았는데, 봉투에는 이름, “Créteil”(당시 살던 인구 약 10만 명 도시), “France” 딱 세 단어만 적혀 있었음
1970년대라 인터넷도 중앙 데이터베이스도 없었지만 우편 서비스가 배달에 성공했음
아버지가 사회복지 활동을 활발히 하고 청소년 축구팀도 운영해서 동네에서 이름만으로도 꽤 알려져 있었기 때문임
요즘은 휴대폰 도움 없이는 사람이나 장소를 못 찾는 경우가 많고, 집배원도 잡담을 멈추지 않음
그런 편지는 기술 처리 과정도, 아마 사람 네트워크도 통과하지 못할 것 같음 - 예전에 덴마크 우편 서비스에서 시간제로 일했는데, 자동 분류는 우편번호까지만 했음
그걸로 편지가 올바른 우체국까지 가면, 나머지는 이른 아침에 집배원들이 처리했음
어떤 주소가 뭘 뜻하는지 맞히는 일이 꽤 재미있었고, 특히 나이 든 직원들은 특정 장소가 왜 그런 식으로 주소가 적히는지 사연을 알거나 거주자 이름만 보고 주소를 추측하곤 했음 - Tom Scott가 이 주제로 만든 좋은 영상이 있음: https://www.youtube.com/watch?v=XxCha4Kez9c
- 미국 주소에는 이상한 예외가 많음
Carmel-by-the-Sea에는 도로 번호가 없고, Florida Keys 주소는 종종 단순히 마일 표지판 번호임
배달이 되는 건 그 경로를 맡은 사람이 익숙하기 때문임 - 인도 주소 기준으로 보면 미국 주소 비표준화는 웃음만 나옴
- 아버지는 한때 알제리에서 온 편지를 받았는데, 봉투에는 이름, “Créteil”(당시 살던 인구 약 10만 명 도시), “France” 딱 세 단어만 적혀 있었음
-
번호판 인식에 초점을 맞춘 공개 모델이 있는지 궁금함
오래된 모델 몇 개는 찾았지만, 이런 OCR 모델처럼 새로 개발 중인 게 있는지 궁금함
직접 이 용도로 써 보고 성능을 확인해볼 수도 있겠음 -
연결된 페이지의 영상이 예상과 달랐음
Mistral은 유럽 AI 회사라고 생각했는데, 영상이 San Francisco에서 촬영됐고 등장하는 세 명도 유럽인처럼 보이지 않아 의외였음
글로벌 조직인 건 좋지만, 파리 사무실과 유럽식 억양을 예상했음- 안타깝게도 유럽 고객은 돈 벌기 어려운 고객임
질문은 많고 지갑은 아주 인색한 반면, 미국인들은 다름 - 어느 정도 규모가 있는 유럽 기술 회사라면 최소한 영업 때문에라도 미국 서부 해안 사무실을 둠
아마 영업 엔지니어링도 있을 것임
시차가 8~10시간이라 사실상 피할 방법이 없음
예전에 일했던 회사는 대신 Vancouver 사무실이 있었고, 같은 시간대였음 - Blackmagic Design도 비슷함
대부분 호주 기반인데도 https://www.blackmagicdesign.com/company/offices의 사무실 목록 순서와 회사 페이지를 보면 미국 회사처럼 보임 - 알기로는 창업팀 대부분이 Meta 같은 미국 회사에서 커리어를 시작했고, 주요 투자자도 미국 VC임
그런 면에서 미국 자금과 유럽 인재라는 양쪽의 이점을 영리하게 누리고 있음 - 배경에 미국 국기까지 높이 걸려 있음
- 안타깝게도 유럽 고객은 돈 벌기 어려운 고객임
-
이 모델이 https://github.com/baidu/Unlimited-OCR와 비교해 어느 정도 순위가 나올지 흥미로움
-
1천 페이지당 4달러면 저렴하지만, 이전 버전들이 전부 “내부 벤치마크 PDF 4개 기준 98% 정확도” 식이었고 실제로는 시장의 거의 모든 대안보다 부족했어서 다시 벤치마크하기가 망설여짐
이번에도 OlmOCRBench와 OmniDocBench에는 “알려진 한계”가 있다며 내부 벤치마크의 대표 수치를 내세우고 있음
https://getomni.ai/blog/benchmarking-open-source-models-for-ocr- 같은 결론이지만, 몇 개 샘플을 직접 돌려보니 2025년 12월 버전 이후로 실제 개선은 보였음
-
모든 AI 연구소는 벤치마크 막대그래프에서 잘린 y축을 쓰는 일을 정말 멈춰야 함
https://mistral.ai/_astro/cm-engish_ZhlvoT.webp?dpl=6a3a94bd1f38530b2974c539 -
Malayalam으로 테스트했는데, 평범한 필체는 정확했지만 조금 다른 스타일은 Kannada로 감지됐음
필요하면 샘플을 줄 수 있고, Sarvam은 같은 샘플에서 텍스트 오류 하나만 남기고 99% 정확도로 처리했음- Sarvam을 인도계 언어 밖에서 써 본 경험이 궁금함
예를 들면 Indian English, 로마자로 적은 인도계 표현이 섞인 문서, 그리고 그림·표 같은 복잡한 레이아웃이 있는 문서에서 어떤지 궁금함
인도 서비스들에 관심은 있었지만, 생각보다 가격이 조금 높아 보이는 편이라 망설이고 있음
물론 잘못 기억하는 것일 수도 있음
- Sarvam을 인도계 언어 밖에서 써 본 경험이 궁금함
-
12월의 이전 OCR v3 모델과 비교해 바운딩 박스 외에 차이가 거의 설명되지 않았고 가격은 두 배임: https://mistral.ai/news/mistral-ocr-3/
당시에는 다른 벤치마크를 썼음 -
“범위 밖 사용에 대한 참고. OCR 4는 문서 이해 모델이지 의사결정자가 아니다. 의료 진단, 법률 자문이나 판단, 고위험 금융 의사결정, 안전 필수 시스템, 실시간/지연 시간 민감 처리, 비문서 입력(원시 오디오, 비디오 등)을 위한 것이 아니다.”
다음 회의에서 “좋아, 그런데 휴대폰 사진 같은 비문서 입력으로 고위험 금융 의사결정에 쓰면 어떨까?”라고 제안할 “혁신적인” 관리자가 벌써 기대됨
다음 주쯤 HN에서 누군가 이 “아이디어”를 댓글로 달 거라고 장담함- 왜 굳이 그렇게 할지 모르겠음
더 성능 좋은 모델이 수십 개 있는데 그에 비해 형편없는 결과만 나올 것임
이건 질문에 답하는 모델이 아니라 텍스트 변환용임
그냥 반AI 각도를 억지로 만들고 싶은 것처럼 보임 - 모든 AI 회사가 한 작업에 아주 강한 전문화 모델을 만들고 있음
Mistral은 이 점을 좀 더 솔직하게 드러낼 뿐이고, 아마 모든 것의 전문가처럼 보이는 범용 사용자 도구(채팅)로 관객을 놀라게 할 필요가 없거나 원하지 않기 때문일 것임
실제로 그런 도구도 꽤 자주 여러 전문 모델을 연결한 형태임
여기서 원하는 건 Python 스크립트 몇 개면 가능함
Voxtral로 음성 프롬프트를 텍스트로 바꾸고, 추가 시스템 프롬프트와 함께 Mistral Large 3에 넘겨 OCR용 프롬프트와 파일 경로를 만들게 한 뒤, 루프로 파일을 찾고 OCR 3에 던지고, 다시 Mistral Large 3으로 해석해서 의사결정으로 바꾸면 됨
이런 구성은 흔하고, 오히려 모든 걸 모델 하나로 처리하는 쪽이 드묾 - “중요 금융 의사결정을 OCR 소프트웨어에 위임했더니, 다음에 벌어진 일을 믿지 못할 겁니다”
- 왜 굳이 그렇게 할지 모르겠음
-
최근 Opus 4.8로 OCR을 시도했음
엄밀히 말해 맞는 도구는 아니지만, 필요한 건 영수증에서 날짜를 추출하는 것뿐이었음
날짜의 약 20%를 틀렸는데도 전부 “높은 신뢰도”라고 평가했음
아마 OCR 특화 모델을 써봤어야 했을 듯함- 영수증에서 날짜 뽑는 건 30년 전쯤 이미 거의 풀린 문제 아니었나 싶음
예전에 흑백 스캐너에 딸려오던 셰어웨어 OCR 도구도 20% 오류보다는 나았을 것 같음 - Opus는 모르겠지만, Gemini의 구독 제품 OCR은 모델이 직접 하는 게 아닌 듯함
별도의 구식 OCR 도구를 쓰는 것 같고, 테스트 결과도 나빴음
반면 Gemini API에서는 모델이 직접 OCR을 해서 훨씬 정확도가 좋았음 - Opus는 OCR을 아주 잘함
작은 1~4B 비전-언어 모델보다 훨씬 나음
Opus가 실패했다면 그런 작은 모델들도 대부분 실패할 가능성이 큼 - 이 얘기는 믿기 어려움
Opus 4.8로 최근 최악의 필체가 섞인 PDF 수백 개를 스캔했는데, 나조차 읽을 수 없던 기록 하나를 제외하면 100% 성공했음
- 영수증에서 날짜 뽑는 건 30년 전쯤 이미 거의 풀린 문제 아니었나 싶음
{kind=link}