- 총 350억 파라미터 중 30억만 활성화되는 희소 Mixture-of-Experts(MoE) 구조로, 효율성과 성능을 동시에 달성한 오픈소스 모델임
- 이전 세대 대비 에이전트형 코딩 능력이 크게 향상되어, Qwen3.5-27B나 Gemma4-31B 같은 대형 밀집 모델과 경쟁 가능한 수준을 보임
- SWE-bench, Terminal-Bench, Claw-Eval 등 주요 코딩 벤치마크에서 높은 점수를 기록하고, 멀티모달 과제에서도 Claude Sonnet 4.5급 성능을 달성함
- Alibaba Cloud Model Studio API, Hugging Face, ModelScope를 통해 공개 가중치와 API 접근이 가능하며, OpenClaw·Claude Code 등 다양한 코딩 도구와 통합 지원함
- 활성 파라미터 30억 개로 대형 모델에 필적하는 효율적 오픈 모델의 새로운 기준을 제시함
Qwen3.6-35B-A3B 개요
- Qwen3.6-35B-A3B는 총 350억 파라미터 중 30억만 활성화되는 희소 Mixture-of-Experts(MoE) 모델로, 효율성과 성능을 동시에 갖춘 오픈소스 모델임
- 이전 버전인 Qwen3.5-35B-A3B보다 에이전트형 코딩(agentic coding) 성능이 크게 향상되었으며, Qwen3.5-27B나 Gemma4-31B 같은 대형 밀집 모델과 경쟁 가능한 수준을 보임
- 멀티모달 추론과 비추론 모드를 모두 지원하며, Qwen Studio, API, Hugging Face, ModelScope를 통해 공개됨
- 모델은 Qwen Studio에서 대화형으로 사용 가능하며, Alibaba Cloud Model Studio API(
qwen3.6-flash)를 통해 호출하거나 직접 호스팅 가능
성능 평가
-
언어 및 코딩 성능
- Qwen3.6-35B-A3B는 활성 파라미터 30억 개만으로 Qwen3.5-27B(밀집형 270억 파라미터)를 여러 주요 코딩 벤치마크에서 능가함
- SWE-bench Verified 73.4, Terminal-Bench 51.5, Claw-Eval 평균 68.7 등에서 높은 점수를 기록
- QwenWebBench(웹 코드 생성 벤치마크)에서는 1397점을 기록해 동급 모델 중 최고 수준
- 일반 에이전트 벤치마크(MCPMark, MCP-Atlas, WideSearch 등)에서도 경쟁 모델 대비 우수한 결과를 보임
- 지식 및 추론 관련 MMLU-Pro, GPQA, AIME26 등에서도 높은 정확도를 유지
-
평가 환경
- SWE-Bench 시리즈는 내부 에이전트 스캐폴드(bash + file-edit 도구) 기반으로 200K 컨텍스트 윈도우에서 평가
- Terminal-Bench 2.0은 3시간 제한, 32 CPU/48GB RAM 환경에서 5회 평균
- SkillsBench는 API 의존 작업을 제외한 78개 과제에서 평가
- QwenClawBench와 QwenWebBench는 내부 실사용 분포 기반 벤치마크로, 실제 사용자 환경을 반영
-
비전-언어 성능
- Qwen3.6-35B-A3B는 자연 멀티모달 모델로, 30억 활성 파라미터만으로 Claude Sonnet 4.5 수준의 성능을 달성
- RefCOCO(공간 인지) 92.0, ODInW13 50.8로 공간 지능에서 강점을 보임
- RealWorldQA 85.3, MMBench EN-DEV 92.8, OmniDocBench1.5 89.9 등 다양한 비전-언어 과제에서 높은 점수
- 비디오 이해 벤치마크(VideoMME, VideoMMMU, MLVU 등)에서도 80~86대의 점수를 유지하며 안정적 성능을 보임
Qwen3.6-35B-A3B 활용
-
배포 및 접근
- Alibaba Cloud Model Studio API(
qwen3.6-flash)를 통해 사용 가능하며, Hugging Face 및 ModelScope에서 오픈 가중치 다운로드 가능 - Qwen Studio에서 즉시 체험 가능하며, OpenClaw, Claude Code, Qwen Code 등 서드파티 코딩 도우미와 통합 지원
- Alibaba Cloud Model Studio API(
-
API 사용
preserve_thinking기능을 지원해 이전 대화의 사고(thinking) 내용을 유지하며 에이전트형 작업에 적합- Alibaba Cloud Model Studio는 OpenAI 및 Anthropic API 규격과 호환되는 chat completions API를 제공
- 예시 코드에서는
enable_thinking옵션을 통해 추론 과정(reasoning trace)과 최종 답변을 구분 출력 가능
-
OpenClaw 통합
- Qwen3.6-35B-A3B는 OpenClaw(구 Moltbot/Clawdbot)와 호환되며, Model Studio와 연결해 터미널 기반 에이전트 코딩 환경 제공
- 설정 파일(
~/.openclaw/openclaw.json)에 Model Studio API 정보를 병합해 사용 - Node.js 22 이상 환경에서 설치 및 실행 가능
-
Qwen Code 통합
- Qwen 시리즈에 최적화된 Qwen Code(터미널용 오픈소스 AI 에이전트)와 완전 호환
- Node.js 20 이상에서 설치 후
/auth명령으로 인증 절차 수행
-
Claude Code 통합
- Anthropic API 프로토콜을 지원해 Claude Code에서도 직접 사용 가능
- 환경 변수로
ANTHROPIC_MODEL="qwen3.6-flash"설정 후 CLI 실행
요약 및 전망
- Qwen3.6-35B-A3B는 희소 MoE 구조로도 대형 밀집 모델에 필적하는 에이전트형 코딩 및 추론 능력을 입증
- 활성 파라미터 30억 개로 효율성과 성능을 모두 달성하며, 멀티모달 벤치마크에서도 우수한 결과를 보임
- 완전한 오픈소스 체크포인트로 공개되어, 효율적 오픈 모델의 새로운 기준을 제시
- Qwen 팀은 Qwen3.6 오픈소스 패밀리를 지속 확장할 예정이며, 커뮤니티의 피드백과 활용을 기대
인용 정보
@misc{qwen36_35b_a3b, title = {Qwen3.6-35B-A3B: Agentic Coding Power, Now Open to All}, url = {https://qwen.ai/blog?id=qwen3.6-35b-a3b}, author = {Qwen Team}, month = {April}, year = {2026}}
댓글과 토론
Hacker News 의견들
-
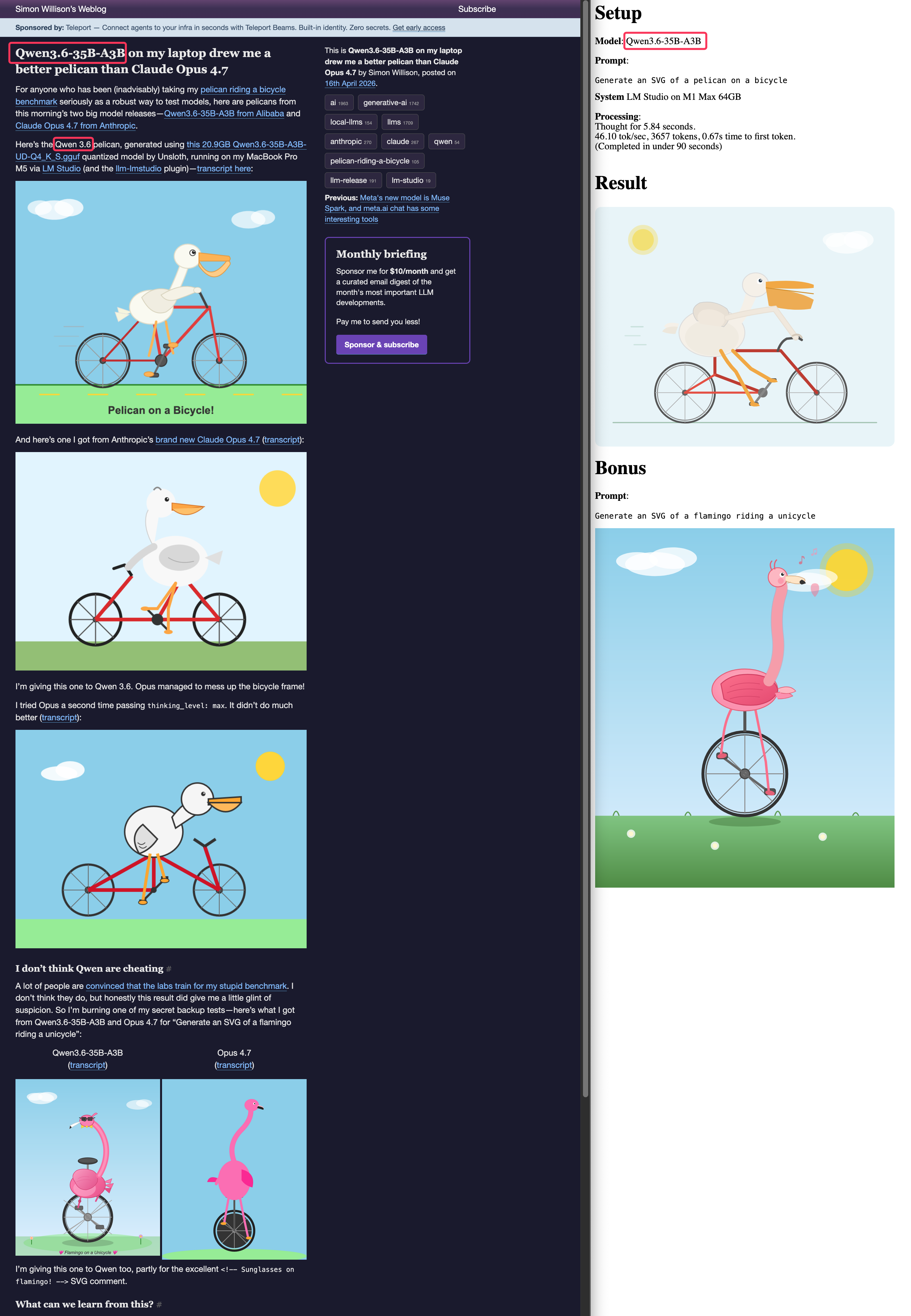
내 노트북에서 Unsloth 20.9GB GGUF 버전을 LM Studio로 돌려봤음
모델 링크
놀랍게도 Opus 4.7보다 자전거 타는 펠리컨을 더 잘 그렸음
Simon Willison의 비교 포스트 참고- 같은 모델로 재현해봤음 (M1 Max 64GB, 90초 미만) — 결과 이미지
내 결과물은 하늘에 태양과 구름, 얇은 초록색 선 형태의 잔디, 그리고 후광이 있는 태양 효과가 있었음
Simon의 결과와 비슷한 ‘공기 흐름’ 표현도 있었지만, 결국 중요한 건 펠리컨과 자전거임 - GGUF 링크 덕분에 시도해봤음
Shoggoth.db 프로젝트에서 wiki 탐색 + 자동 DB 구축 작업에 사용했음
Qwen3.5보다 새로운 생물 탐색 능력이 향상된 걸 체감했음
속도도 약 140 token/s로 빨라졌고, RTX 4090에서 메모리 오프로드 없이 안정적으로 작동했음
단, 멀티모달 충돌 방지를 위해--no-mmproj-offload옵션을 써야 했음 - ‘자전거 타는 펠리컨’ 같은 테스트가 언제쯤 쓸모없어질지 궁금함
원래는 아무도 생각하지 않았던 이상한 프롬프트로 모델의 창의성을 평가하려는 의도였는데, 이제는 내부 벤치마크처럼 되어버린 느낌임 - Qwen의 플라밍고 그림이 왜 이겼는지 모르겠음
타이어 위에 앉아 있고, 부리 위치도 이상하며, 바퀴살과 다리 비율이 어색함
선글라스도 반투명해서 눈이 하나만 보임
귀엽긴 하지만 요청하지 않은 보타이와 액세서리 때문에 오히려 감점 요인이라 생각함
Opus의 결과가 덜 화려하지만 더 정확했음 - 이미지를 보면 볼수록 world model이 여전히 빠진 퍼즐 조각 같음
결국 지금 모델들은 확률적 문장 생성기에 불과하다는 생각이 듦
- 같은 모델로 재현해봤음 (M1 Max 64GB, 90초 미만) — 결과 이미지
-
Qwen 팀이 오픈 가중치를 계속 공개하는 걸 보니 다행임
관련 뉴스1, 뉴스2
Junyang Lin 등 주요 인력 이탈 이후에도 프로젝트가 이어지는 게 인상적임- Qwen 3.6 시리즈 중 하나일 뿐임
작은 사이즈 모델들은 곧 공개될 가능성이 높지만, 주력 397A17B 모델은 제외된 듯함 - 개인적으로는 qwen-image 2.0의 오픈 가중치 공개를 바람
- Qwen 3.6 시리즈 중 하나일 뿐임
-
Unsloth가 이미 양자화 및 변환을 완료한 버전이 있음
Hugging Face 링크- Unsloth는 빠르게 실험용 quants를 올리지만, 출시 직후 버전은 종종 수정됨
일주일쯤 후에 다시 확인해야 안정된 버전을 받을 수 있음
초기 버그 때문에 좋은 모델이 과소평가되는 경우도 있음 - Qwen이 직접 quantized 모델을 내지 않는 이유가 궁금함
양자화 과정이 복잡하고 품질 저하 위험이 있어서, 원 개발자가 직접 하는 게 낫다고 생각함
잘못된 quant 버전이 모델 평판을 망칠 수도 있음 - VRAM 요구량이 궁금함. 16GB GPU로도 돌릴 수 있을지 알고 싶음
- Qwen의 기본 quantization이 왜 나쁜지, Unsloth가 누구인지,
그리고 좋은 포맷이 주는 이점이 뭔지 궁금함
quantization 자체의 개념도 함께 설명해주면 좋겠음 ollama run claude명령으로도 이 모델을 쓸 수 있는지 궁금함
- Unsloth는 빠르게 실험용 quants를 올리지만, 출시 직후 버전은 종종 수정됨
-
Qwen 팀의 이번 릴리스가 반가움
소형 오픈웨이트 코딩 모델은 특정 산업(예: 금융, 헬스케어)에서
클라우드 접근이 제한된 개발팀에게 맞춤형 에이전트를 만드는 데 유용함
서구권에서는 이런 시장을 거의 다루지 않는데, Mistral만이 예외인 듯함- Mistral은 지속 가능한 비즈니스 모델을 추구하는 유일한 회사로 보임
다른 AI 기업들은 단기 수익만 노리는 느낌임 - 작은 오픈 모델은 재미있지만, 대형 호스팅 모델과는 급이 다름
진지한 작업이라면 더 큰 모델을 직접 돌릴 수 있는 하드웨어에 투자해야 함 - 공감하지만, 이런 소형 모델은 실제 산업용으로는 부족함
10만 달러 정도의 장비로도 더 큰 모델을 온프레미스로 돌릴 수 있음 - 오픈웨이트 경쟁 모델을 만드는 건 멋지지만 비용이 너무 큼
- 규제 산업에서는 모델이 악의적 데이터로 학습되지 않았음을 검증하는 방법이 궁금함
- Mistral은 지속 가능한 비즈니스 모델을 추구하는 유일한 회사로 보임
-
Qwen의 언어 임베딩 특성이 흥미로움
관련 분석 트윗
Qwen은 다른 모델들과 달리 시험 중심적 분포(basin) 에 위치한다고 함 -
Qwen 임원이 트위터에서 어떤 모델을 오픈소스로 보고 싶은지 투표를 올렸는데,
27B 버전이 가장 인기였음에도 불구하고 공개되지 않았음- 3.5 때처럼 distillation 과정을 거쳐 순차적으로 공개될 가능성이 있음
A3B 구조는 증류 속도가 빠르기 때문에 곧 나올 수도 있음 - 27B는 dense 모델이라 마케팅 측면에서 35A3B보다 덜 매력적임
후자가 더 빠르고 ‘영리하게’ 느껴짐 - 아마 곧 공개될 듯함
- 개인적으로는 MoE 구조가 비효율적이라 생각함
같은 VRAM이라면 27B dense 모델이 더 큰 컨텍스트를 다룰 수 있어 품질이 높을 것임
- 3.5 때처럼 distillation 과정을 거쳐 순차적으로 공개될 가능성이 있음
-
로컬 테스트에서 Qwen3.5-35B-A3B를 많이 써봤는데,
내 장비에서 돌아가는 모델 중 가장 강력했음
특히 Mudler APEX-I-Quality와 Byteshape Q3_K_S-3.40bpw quant 버전이 인상적이었음
RTX 3060 12GB 환경에서 메모리 여유가 생기고 속도도 40 t/s 이상으로 향상됨- 여러 작업을 해보니 Qwen3.6은 3.5보다 훨씬 큰 도약임
이전에 막혔던 프로젝트 개선도 스스로 해냄 - 어떤 quant 버전이 가장 좋은지 궁금함
- 여러 작업을 해보니 Qwen3.6은 3.5보다 훨씬 큰 도약임
-
이런 종류의 AI 소프트웨어 릴리스를 가장 기대하고 있음
과장된 위험 마케팅도 없고, 구독료도 없으며, 순수하게 써보고 싶은 모델임- 나도 같은 생각임. 가까운 미래에는 로컬 모델과 하드웨어 성능이 충분히 올라
대부분의 사용 사례에서 실용적이 되길 바람
- 나도 같은 생각임. 가까운 미래에는 로컬 모델과 하드웨어 성능이 충분히 올라
-
사람들은 이런 로컬 모델을 실제로 어떻게 쓰는지 궁금함
Anthropic이나 OpenAI의 토큰을 빌리는 것보다 어떤 가치가 있는지 알고 싶음- Qwen3.5-9B를 로컬 OCR 테이블 추출에 사용 중임
문서 포맷이 제각각이라 기존엔 복잡한 규칙 기반 파이프라인을 썼는데,
이제는 멀티모달 능력으로 언어+비전 조합 추출이 가능해짐 - 나는 Frigate라는 FOSS NVR과 함께 Qwen3.5-4B를 사용함
영상 분석에 충분히 쓸 만하고, 텍스트 요약이나 번역은 더 큰 모델로 처리함
실시간이 아니면 속도보다 품질이 중요하므로 배치 처리에 적합함 - 나는 토큰 임대 모델을 영원히 쓰고 싶지 않음
완전히 프라이빗한 셀프호스팅 모델을 원함
SaaS 서비스의 중단에 지쳐서, LLM도 결국 자가 호스팅으로 가야 한다고 생각함 - vLLM + qwen3-coder-next로 수백만 문서를 배치 처리했음
토큰 제한이나 속도 제한 없이 GPU 100% 활용 가능했음 - 모든 작업이 SOTA 모델을 필요로 하진 않음
예를 들어 Gemma 4를 아이폰에서 오프라인 번역기로 쓰는데,
Apple Translate보다 빠르고 정확함
작은 JSON 수정 작업 같은 경우 로컬 모델이 훨씬 효율적임
- Qwen3.5-9B를 로컬 OCR 테이블 추출에 사용 중임
{kind=link}