- AI 코딩 도구의 광범위한 도입과 비용 증가 속에서, 유명 기술 기업들이 실제 AI의 효용을 수치화하는 방법을 다층 지표로 정리
- 핵심은 기존의 엔지니어링 기본 지표(예: PR 처리량, 변경 실패율)와 AI 전용 지표(예: AI 사용률, 시간 절감, CSAT)를 함께 추적하는 혼합 접근법
- 팀/개인/코호트별로 AI 사용 수준에 따른 분해와 전후 비교를 통해 추세와 상관관계를 도출하는 실험적 사고방식 강조
- 품질·유지보수성·개발자 경험을 속도 지표와 함께 상시 감시하여 기술 부채 증가와 단기 편익의 역효과를 방지하는 균형 설계가 필요
- 장기적으로는 에이전트 원격계측과 비코딩 작업영역까지 확장 측정이 예고되며, 질문은 “AI가 이미 중요한 것(품질·시장 출시 속도·개발자 경험)을 더 낫게 만들고 있는가”로 귀결됨
AI 임팩트 담론과 측정 격차
- LinkedIn 등에서 흔히 볼 수 있듯이, AI가 기업 소프트웨어 개발 방식을 바꾸고 있다는 주장이 넘쳐남
- Google 25%, Microsoft 30% 등 대규모 AI 코드가 실제 프로덕션 코드로 배포된다는 보도가 이어짐
- 일부 창업자는 AI가 주니어 엔지니어를 대체할 수 있다고 주장하는 반면, METR 연구는 시간 지각 왜곡과 생산성 저하 가능성을 보여줌
- 언론은 AI 임팩트를 “코드를 얼마나 많이 썼는가” 로 단순화해 전달하지만, 그 결과 업계는 사상 최대 규모의 기술 부채 누적 위험에 직면함
- LOC(라인 수)는 생산성 지표로 부적합하다는 합의가 있었음에도 불구하고, 측정 용이성 때문에 다시 부상하며 품질, 혁신, 출시 속도, 신뢰성 같은 본질적 가치가 가려짐
- 현재 많은 엔지니어링 리더들은 무엇이 효과적이고 아닌지 명확히 알지 못한 채 AI 도구에 대한 중대한 의사결정을 내리고 있음
- LeadDev의 2025 AI Impact Report에 따르면 리더의 60%가 ‘명확한 지표 부재’를 최대 과제로 지적
- 현장의 리더들은 성과 압박과 LOC 집착 경영진 사이에서 불만을 느끼며, 필요한 정보와 실제 측정 사이의 간극은 점점 확대됨
- 필자는 10년 이상 개발자 도구를 연구하며, 2021년 이후에는 생산성 향상과 AI 임팩트 측정 자문을 수행 중임
- DX CTO로 합류한 이후 수백 개 기업과 협업하며 DevEx·효율성·AI 영향 분석을 주도
- 2025년 초에는 400개 이상의 기업 데이터를 기반으로 AI Measurement Framework를 공동 저술
- 이는 AI 도입과 영향 측정에 필요한 권장 지표 세트로, 현장 연구와 데이터 분석을 토대로 구축됨
- 이번 글에서는 18개 테크 기업이 실제로 AI 임팩트를 측정하는 방식을 살펴보고,
- Google, GitHub, Microsoft 등의 실제 지표 사례
- 무엇이 효과적인지 파악하는 활용법
- AI 임팩트 측정 방법론
- AI 임팩트 지표 정의 및 가이드를 공유함
1. 18개 기업의 실제 측정 지표
- Google, GitHub, Microsoft, Dropbox, Monzo, Atlassian, Adyen, Booking.com, Grammarly 등 18개사 사례를 이미지로 공유
- 기업들이 서로 다른 접근을 취하지만, 공통적으로 몇 가지 핵심 지표군에 집중하고 있음
-
1. 사용 지표 (Adoption & Usage)
- DAU/WAU/MAU: 거의 모든 회사가 AI 도구의 일간·주간 활성 사용자 추적
- 사용 강도/사용 이벤트: Google, eBay 등은 코드 작성, 채팅 응답, agentic actions까지 세분화
- AI tool CSAT: Dropbox, Webflow, Grammarly 등 다수 기업이 만족도 조사 병행
-
2. 생산성 지표 (Throughput & Time Savings)
- PR 처리량(PR throughput): GitHub, Dropbox, Webflow, CircleCI 등 다수 기업이 공통적으로 추적
- 시간 절감(Time savings): 엔지니어별 주간 절감 시간 측정 (Dropbox, Monzo, Toast, Xero 등)
- PR 사이클 타임: Microsoft, CircleCI, Xero, Grammarly 등에서 사용
-
3. 품질/안정성 지표 (Quality & Reliability)
- Change Failure Rate: GitHub, Dropbox, Adyen, Booking.com, Webflow 등 가장 흔한 품질 지표
- 코드 유지보수성/품질 인식: GitHub, Adyen, CircleCI 등 DevEx와 연결해 평가
- 버그/되돌림률: Glassdoor(버그 수), Toast(PR revert rate)
-
4. 개발자 경험 지표 (Developer Experience)
- 개발자 만족도/설문(DevEx, DXI): Atlassian, Webflow, CarGurus, Vanguard 등에서 활용
- Bad Developer Days (BDD): Microsoft는 독창적으로 ‘나쁜 개발자 하루’ 개념으로 마찰 측정
- 인지 부하·개발자 friction: Google, eBay 등
-
5. 비용 및 투자 지표 (Spend & ROI)
- AI 지출(total & per developer): Dropbox, Grammarly, Shopify 사례처럼 일부 기업은 비용 추적
- Capacity worked (활용률): Glassdoor는 도구가 최대 잠재력 대비 얼마나 쓰였는지 측정
-
6. 혁신/실험 지표 (Innovation & Experimentation)
- Innovation ratio / velocity: GitHub, Microsoft, Webflow 등은 혁신 속도를 지표화
- A/B 테스트 수: Glassdoor는 월간 A/B 테스트 건수를 핵심 지표로 삼음
- 시간 절감, PR 처리량, 변경 실패율, 참여 사용자, 혁신률 등 성과 지표와 사용 행태 지표를 병행 추적함
- 조직별로 우선순위와 제품 맥락에 따라 지표 구성이 상이하며, 단일 만능 지표는 없음
2. 견고한 기반: AI 임팩트 측정의 핵심
- AI로 코드를 작성한다고 해서 좋은 소프트웨어의 기준이 달라지지 않음. 여전히 품질, 유지보수성, 속도는 핵심
- 따라서 변경 실패율(Change Failure Rate), PR 처리량, PR 사이클 타임, 개발자 경험(DevEx) 같은 기존 지표가 여전히 중요함
-
완전히 새로운 지표는 불필요
- 중요한 질문은 “AI가 기존에 중요하던 것들을 더 잘하게 만들고 있는가?”임
- LOC나 수용률 같은 표면적 지표에 머물면 AI 임팩트를 제대로 파악할 수 없음
-
AI 사용에서 정확히 무슨 일이 일어나고 있는지 파악하기 위해서는 새로운 타겟 지표가 필요
- 어디서, 얼마나, 어떤 방식으로 AI가 사용되는지를 파악해 예산·도구 롤아웃·보안·컴플라이언스 같은 의사결정에 활용할 수 있음
- AI 메트릭은 이런 것들을 보여줌:
- AI 툴을 도입하는 개발자의 수와 유형은 얼마나 되나?
- AI가 얼마나 많은 작업과 어떤 종류의 작업에 영향을 미치는가?
- 비용은 얼마인가?
- 핵심 엔지니어링 지표는 이런 것을 보여줌:
- 팀이 더 빠르게 쉬핑하는지
- 품질과 신뢰도가 올라가는지/내려가는지
- 코드 유지보수성이 내려가는지
- AI도구들이 개발자 워크플로우에서 마찰을 줄이고 있는지
-
Dropbox 사례를 보면
-
AI 지표
- DAU/WAU (일간·주간 활성 사용자)
- AI tool CSAT (만족도)
- 엔지니어별 시간 절감
- AI 지출
-
코어 지표 (Core 4 Framework 활용)
- Change Failure Rate
- PR throughput
-
성과
- 주간 정기 AI 사용자 = 전체 엔지니어의 90% (업계 평균 50%보다 높음)
- AI 정기 사용자는 PR 병합 20% 증가 + 변경 실패율 감소
- 도입률 자체보다 조직·팀·개인 성과에 실질적 기여하는지 확인이 핵심임
-
AI 지표
3. AI 사용 수준별 지표 분해
-
AI가 개발자 업무 방식에 어떤 변화를 주는지 이해하기 위해 다양한 비교 분석을 수행
- AI 사용자 vs 비사용자 비교
- AI 도구 도입 전후의 핵심 엔지니어링 지표 비교
- 동일 사용자 집단을 추적(cohort analysis)하여 AI 도입 이후 변화 관찰
-
데이터를 세분화(slicing & dicing)하여 패턴 도출
- 역할, 근속연수, 지역, 주요 언어 같은 속성별로 분석
- 예: 주니어는 PR 작성이 늘고, 시니어는 리뷰 비중 증가로 속도가 느려지는 현상
- 이를 통해 추가 교육·지원이 필요한 그룹과 AI 활용 효과가 큰 그룹을 식별 가능
-
Webflow 사례
- 근속 3년 이상 개발자 집단에서 AI 활용 시 시간 절감 효과가 가장 컸음
- Cursor, Augment Code 등 도구 활용 시 PR 처리량 20% 증가 (AI 사용자 vs 비사용자 비교)
-
견고한 베이스라인의 필요성
- 개발자 생산성 지표 기반이 없는 조직은 AI 임팩트 측정이 어려움
-
Core 4 프레임워크(Dropbox, Adyen, Booking.com 등 활용)로 빠르게 기본선 확보 가능
- 템플릿 및 가이드 참고
- 시스템 데이터·경험 표집 데이터·정기 설문을 함께 활용해 신뢰도 높은 비교 수행
-
지속적 추적과 실험적 사고방식이 핵심
- 일회성 측정으로는 의미 없음, 시계열 추적을 통해 추세와 패턴을 파악해야 함
- 성공 기업들의 공통점: 구체적 목표를 세우고 데이터를 통해 가설 검증
- 데이터를 맹목적으로 의존하지 않고, 목표 중심적 실험 마인드셋을 유지
4. 유지보수성·품질·개발자 경험에 대한 경계
-
AI 보조 개발은 여전히 새로운 영역
- 장기적인 코드 품질·유지보수성에 미치는 영향을 입증할 데이터가 부족
- 단기 속도 향상과 장기 기술 부채 리스크 사이의 균형이 핵심 과제
-
상호 견제하는 지표를 함께 추적해야 함
- 대부분의 기업은 변경 실패율(Change Failure Rate) 과 PR 처리량을 동시에 추적
- 속도는 오르지만 품질이 떨어지는 경우, 즉각적인 문제 신호로 작용
-
품질·유지보수성 감시를 위한 추가 지표
- Change confidence: 배포 시 코드 안정성에 대한 개발자 확신도
- Code maintainability: 코드 이해·수정 용이성
- Perception of quality: 팀 차원의 코드 품질·관행에 대한 개발자 인식
-
시스템 지표와 자기보고 지표의 결합 필요
- 시스템 데이터: PR 처리량, 배포 빈도 등
- 자기보고 데이터: 변경 신뢰도, 유지보수성 등 → 장기적인 부정적 영향을 방지하는 핵심 신호
-
정기적인 개발자 경험(DevEx) 설문 권장
- 설문 예시를 통해 품질·유지보수성과 AI 사용 상관관계 추적 가능
- 비정형 피드백도 기존 문제 파악과 해결책 논의에 유용
-
개발자 경험(DevEx)의 실제 의미
- “탁구·맥주”와 같은 복지 개념이 아닌 개발 과정 전반의 마찰 제거
- 기획→개발→테스트→배포→운영 전 과정에서의 효율성 확보를 목표로 함
- AI 도구가 코드 작성·테스트의 마찰을 줄이면서, 리뷰·사고 대응·유지보수에 새로운 마찰을 추가할 위험 존재
-
현장 인사이트 (CircleCI Shelly Stuart)
- 출력 지표(PR 처리량)는 무엇이 일어나는지 보여주지만, 개발자 만족도는 지속 가능성을 보여줌
- AI 도입은 초기 불편을 초래할 수 있으므로, 만족도 추적은 단기 마찰 vs 장기 가치를 구분하는 핵심 도구
- 75%의 기업이 AI 도구의 CSAT/만족도를 함께 추적 → 속도보다 지속 가능한 개발 문화 조성에 초점
5. 독특한 지표와 흥미로운 동향
-
Microsoft: Bad Developer Day (BDD)
- 일상 업무의 마찰과 피로도를 실시간으로 측정하는 개념
- 사건 대응·컴플라이언스 처리, 회의·이메일 전환 비용, 작업 관리 시스템에 소모되는 시간 등이 하루를 나쁘게 만드는 요인
- PR 활동(코딩 시간 대리 지표)과 균형해, 일부 저가치 업무가 있더라도 코딩에 일정 시간을 확보하면 좋은 하루로 평가
- 목표: AI 도구가 BDD 빈도·심각도를 줄이고 있는지 확인
-
Glassdoor: 실험과 도구 활용률 측정
- 월간 A/B 테스트 건수로 AI가 혁신·실험 속도를 높이는지 추적
- 파워 유저를 내부 AI 전도사로 키우는 전략 병행
- Capacity worked(활용률): 도구의 잠재적 사용량 대비 실제 사용량을 측정해 도입 포화 시점과 예산 재배치 판단
-
Acceptance Rate의 하락
- 과거에는 핵심 AI 지표였으나, 제안 수용 순간만 보기에 범위가 협소
- 유지보수성, 버그 발생, 코드 되돌림, 개발자 체감 생산성 등은 반영하지 못함
- 현재는 최상위 지표로 잘 쓰이지 않으나 예외 있음:
- GitHub: Copilot 개선과 제품 의사결정에 활용
- T-Mobile: AI 코드가 실제 프로덕션에 반영되는 정도 추정
- Atlassian: 개발자 만족도 및 제안 품질 보조 지표로 사용
-
비용·투자 분석
- 대부분의 기업은 개발자 위축을 막기 위해 사용 비용을 적극 추적하지 않음
- Shopify는 AI Leaderboard로 토큰 소비량이 많은 개발자를 축하하는 방식 채택
-
ICONIQ 2025 State of AI Report: 2025년 기업 내 AI 생산성 예산이 2024년 대비 두 배 증가 전망
- 일부는 채용 예산을 줄이고 AI 도구 예산에 재할당하는 방식으로 전환
-
에이전트 텔레메트리의 부재
- 현재는 측정이 거의 없으나 12개월 내 도입 가능성 높음
- 자율형 에이전트 워크플로우가 확산되면 행동·정확도·회귀율 등을 계측해야 할 필요가 커짐
-
비코딩 활동 측정의 부족
- 현재는 코드 작성 지원에 한정, ChatGPT 기획 세션이나 Jira 이슈 처리 등은 잘 포함되지 않음
- 2026년에는 SDLC 전체 단계에서 AI 활용이 확대되며 측정도 진화 필요
- 코드 리뷰, 취약점 검사 같은 구체적 활동은 측정 용이, 추상적 작업은 측정 어려움
- 자기보고식 측정(“이번 주 AI로 얼마나 시간을 절약했는가?”)의 범위 확장이 예상됨
6. AI 임팩트는 어떻게 측정해야 하는가?
-
AI Measurement Framework
- DevEx Framework 공동 저자인 Abi Noda와 함께 개발
- 400여 개 기업의 현장 데이터와 지난 10여 년간의 개발자 생산성 연구를 바탕으로 작성
- AI 지표와 코어 지표를 결합해 속도·품질·유지보수성·개발자 경험(DevEx)을 함께 평가
- 단일 지표(예: AI 생성 코드 비율)는 headline에는 적합하나 충분한 성과 측정 수단이 아님
-
정성적 + 정량적 데이터 병행 필요
- 시스템 지표(PR 처리량, DAU/WAU, 배포 빈도 등)와 자기보고 지표(CSAT, 시간 절감, 유지보수성 인식 등)를 모두 수집해야 다차원적 이해 가능
- 많은 기업이 DX를 활용해 데이터 수집 및 시각화 수행, 커스텀 시스템 구축도 가능
-
데이터 수집 방법
- 시스템 데이터(정량): AI 도구의 관리 API(사용·지출·토큰·수용률) + SCM·JIRA·CI/CD·빌드·사고관리 지표
- 정기 설문(정성): 분기/반기 설문으로 DevEx·만족도·변경 신뢰도·유지보수성 등 시스템 지표로는 얻기 힘든 장기적 추세 파악
- 경험 표집(정성): 워크플로우 중 짧은 질문 삽입 (예: PR 제출 직후 “AI를 사용했는가?”, “이 코드가 이해하기 쉬웠는가?”)
-
실행 우선순위
- 정기 설문이 가장 빠른 시작점: 1~2주 내 초기 데이터 확보 가능
- 커튼을 달 때와 로켓을 쏠 때의 정밀도는 다르듯, 엔지니어링 의사결정은 충분한 방향성을 주는 정도의 정확도로도 의미 있음
- 이후 다른 데이터 수집 방식을 병행해 교차 검증하면 신뢰성 상승
-
추가 리소스
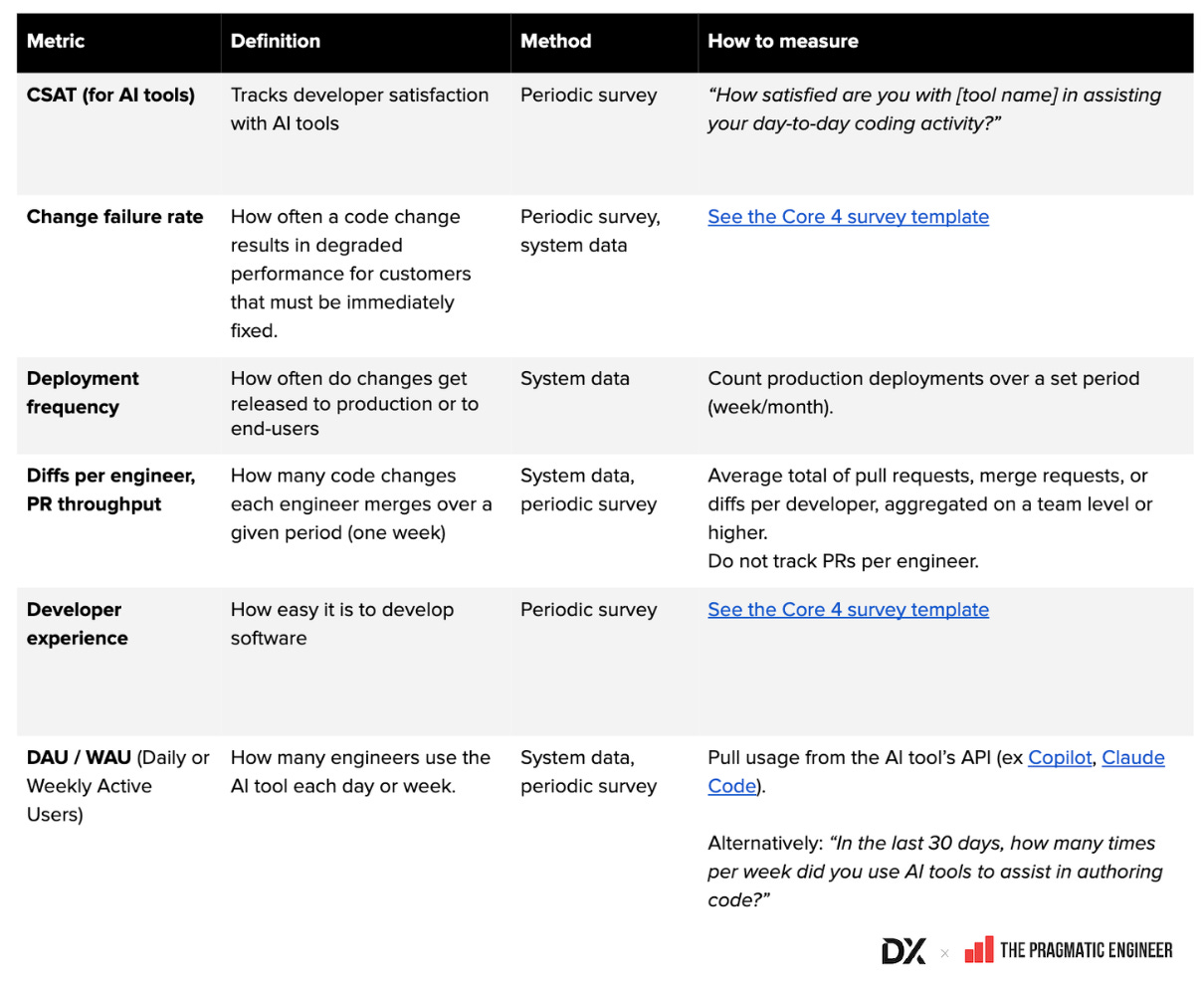
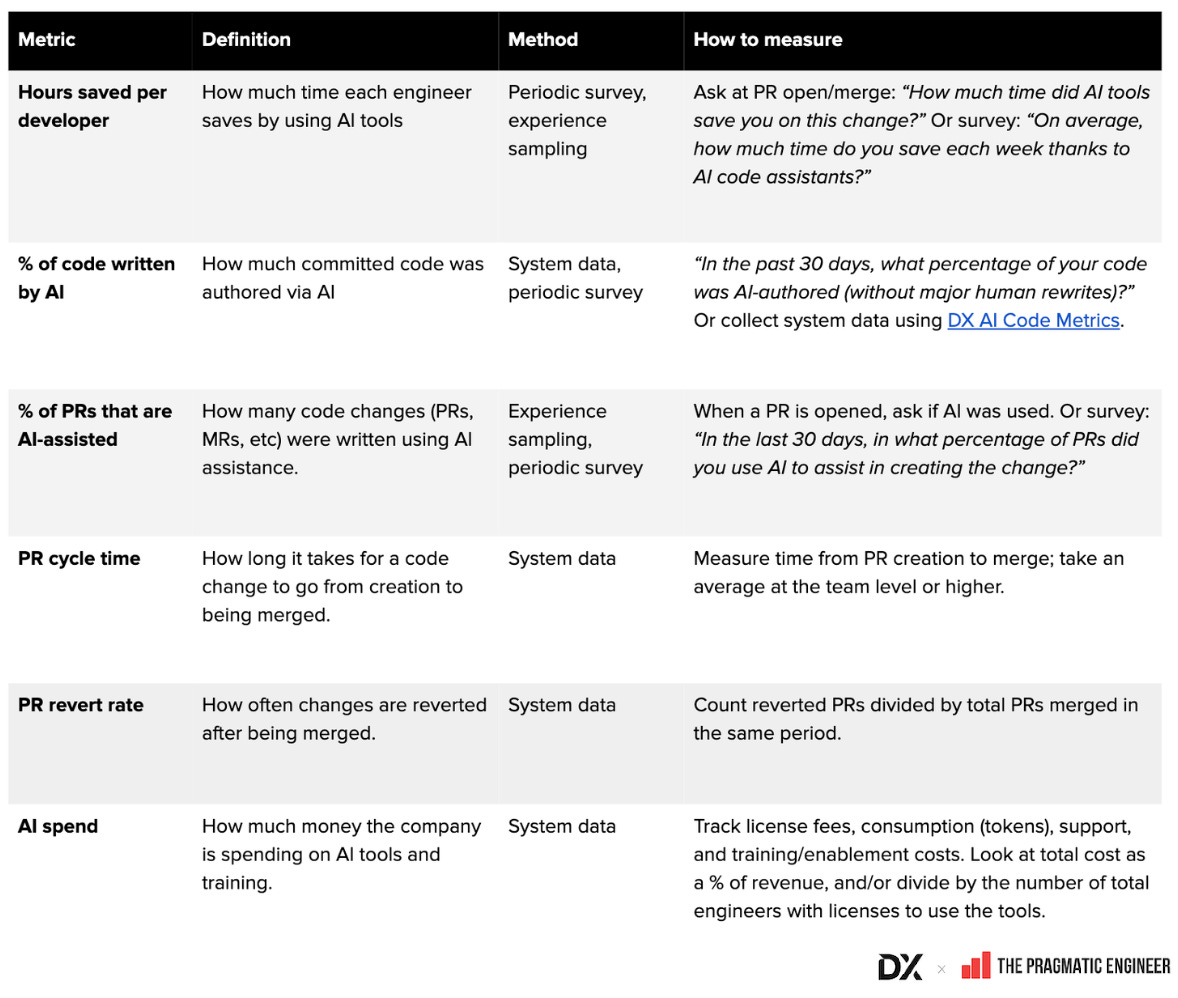
- 공통 AI 지표 글로서리 (Google Sheet): 정의·계산법·수집 방법 정리
- AI 및 개발자 생산성 지표 예시 이미지
-
내부 적용 시 고려사항
- 채택률이나 단일 지표를 쫓는 것이 아니라, 고품질 소프트웨어를 빠르게 고객에게 전달하는 능력이 향상되는지 확인해야 함
- 핵심 질문:
> “AI가 이미 중요한 것(품질, 출시 속도, 개발자 경험)을 더 낫게 만들고 있는가?” - 리더십 회의에서 다룰 질문들:
- 우리 조직의 엔지니어링 성과 정의는 무엇인가?
- AI 도구 도입 전 성과 데이터는 확보했는가? 없으면 어떻게 빠르게 baseline을 마련할 것인가?
- AI 활동을 AI 임팩트로 착각하고 있지는 않은가?
- 속도·품질·유지보수성 간 균형을 맞추고 있는가?
- 개발자 경험에 대한 영향은 보이고 있는가?
- 시스템 데이터와 자기보고 데이터를 모두 포함하는 다층적 측정 방식을 운영하고 있는가?
{kind=link}
{kind=link}
7. Monzo의 AI 임팩트 측정 방식
-
도입 초기
- 첫 도구는 GitHub Copilot. GitHub 라이선스에 포함되며 VS Code에 자연스럽게 녹아들어 모든 엔지니어가 사용 시작
- 이후 Cursor, Windsurf, Claude Code 등 다양한 툴을 병행 테스트하며 Copilot 중심으로 계속 투자
-
AI 도구 평가 철학
- 빠르게 변하는 툴 생태계에서 직접 경험이 필수
- 팀원들이 실제 코드에 AI를 매일 적용하고, 에이전트 설정 파일까지 직접 만들어 써봐야 성능을 알 수 있음
- 평가에는 객관적 지표(사용량, 성능) 와 주관적 설문(DX 만족도) 를 병행
-
효과와 체감 가치
- 엔지니어들이 AI를 통해 문서 검색·요약·코드 이해를 더 쉽게 하고 인지 부하를 줄였다고 느낌
- 경쟁적 인재 시장에서 최고 도구를 제공하지 않으면 개발자 이탈 위험 → 도구 제공 자체가 인재 유지 전략
-
측정의 어려움
- 벤더들이 제공하는 수치는 수용률 같은 제한적 지표에 그치며, 진짜 비즈니스 임팩트는 파악 어려움
- A/B 테스트로 정확히 검증하는 것도 현실적으로 불가능
- 다양한 툴(GitHub, Gemini, Slack, Notion 등)의 사용 데이터를 종합하기 어려움 → 텔레메트리 제한과 벤더 락인이 주요 장애
- 결과적으로 지금은 개발자 체감이 주된 신호
-
잘 작동하는 영역
- 마이그레이션에서 큰 성과: 코드 변경 작업의 40~60% 절감 체감
- 데이터 모델 주석 작업처럼 반복적이고 수동적인 작업에서 LLM이 1차 초안 작성, 엔지니어가 교정 → 대규모 노동 절감
-
예상 밖의 교훈
- LLM 비용 감각 부족: 실제 토큰 사용량에 대한 청구서를 보면 최적화 필요성을 더 체감할 것
- 예: Copilot 자동 코드 리뷰는 토큰을 많이 쓰고 성과는 적어, 기본은 끄고 필요시 opt-in 방식으로 전환
-
AI를 쓰지 않는 영역
- 고객 데이터 관련: 원본/비식별 데이터 모두 AI에 적용 금지
- 민감한 데이터 영역에서 데이터 누출 위험 방지를 최우선으로 함
-
플랫폼 팀 철학
- Guardrails 제공: 데이터 보호 등 안전한 사용 환경 마련
- 사례 공유: 성공/실패 사례와 프롬프트 활용 경험 투명하게 공개
- 양면성 강조: 긍정·부정 모두 공유하며 균형 잡힌 시각 유지
- LLM 한계 상기: AI는 인간처럼 제한이 있으므로 과신하지 않도록 주지
결론 및 시사점
-
AI 임팩트 측정은 아직 매우 새로운 영역
- 업계에 “최선의 방법론”은 존재하지 않음
- Microsoft, Google처럼 규모와 시장이 비슷한 기업도 서로 다른 지표를 사용
- 기업별로 고유한 방식과 “flavor”가 존재
-
상충하는 지표를 동시에 측정하는 것이 일반적
- 대표적 사례: 변경 실패율(신뢰성) 과 PR 빈도(속도) 를 함께 추적
- 빠른 배포가 신뢰성을 해치지 않는 선에서 의미가 있으므로, 두 축을 균형 있게 측정해야 함
-
AI 도구 임팩트 측정은 개발자 생산성 측정과 유사한 난제
- 생산성 측정은 10년 넘게 업계가 씨름해온 문제
- 단일 지표로 팀 생산성을 설명할 수 없으며, 특정 지표에 최적화한다고 생산성이 실제로 높아지지 않음
- 2023년 McKinsey는 생산성 측정법을 “해결했다”고 발표했으나, Kent Beck과 필자는 이에 회의적 입장을 제시 → 반박 기사
-
아직 명확한 해법은 없지만, 실험은 필요
- 생산성 측정을 완전히 해결하기 전까지, AI 도구 임팩트 측정도 완전히 풀리기 어려움
- 그럼에도 불구하고 “AI 코딩 도구가 개인·팀·회사 단위의 일상/월간 효율성을 어떻게 바꾸는가?” 라는 질문에 답하기 위해 계속 실험하고 새로운 접근을 시도해야 함